Contrastive Representations for Temporal Reasoning
Alicja Ziarko, Michal Bortkiewicz, Michal Zawalski, Benjamin Eysenbach, Piotr Milos
NeurIPS 2025
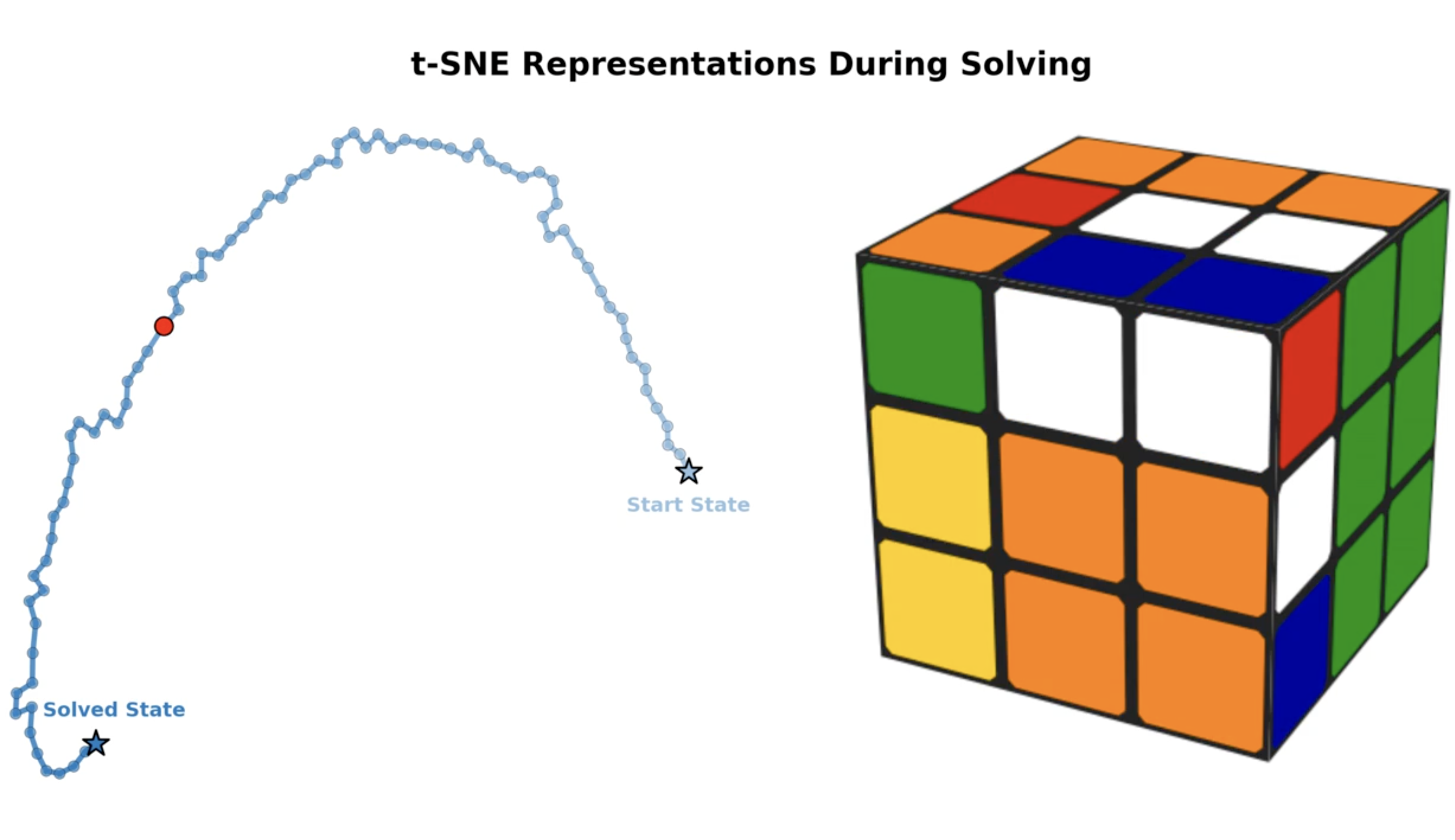
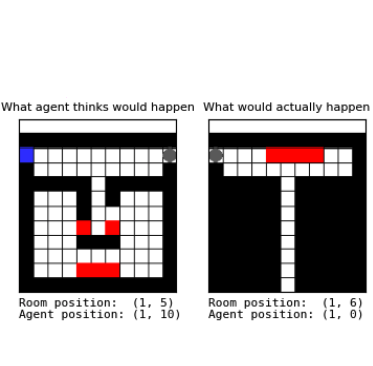
In classical AI, perception relies on learning state-based representations, while planning, which can be thought of as temporal reasoning over action sequences, is typically achieved through search. We study whether such reasoning can instead emerge from representations that capture both perceptual and temporal structure. We show that standard temporal contrastive learning, despite its popularity, often fails to capture temporal structure due to its reliance on spurious features. To address this, we introduce Combinatorial Representations for Temporal Reasoning (CRTR), a method that uses a negative sampling scheme to provably remove these spurious features and facilitate temporal reasoning. CRTR achieves strong results on domains with complex temporal structure, such as Sokoban and Rubik's Cube. In particular, for the Rubik's Cube, CRTR learns representations that generalize across all initial states and allow it to solve the puzzle using fewer search steps than BestFS, though with longer solutions. To our knowledge, this is the first method that efficiently solves arbitrary Cube states using only learned representations, without relying on an external search algorithm.
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Jan Ludziejewski, Maciej Pióro, Jakub Krajewski, Maciej Stefaniak, Michał Krutul, Jan Małaśnicki, Marek Cygan, Piotr Sankowski, Kamil Adamczewski, Piotr Miłoś, Sebastian Jaszczur
ICML 2025
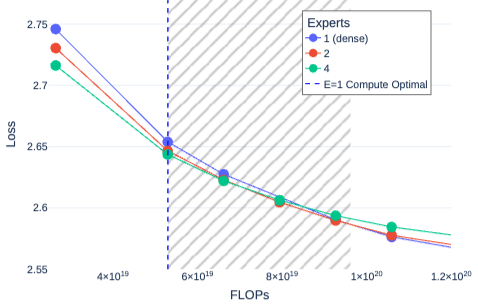
Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
Since Faithfulness Fails: The Performance Limits of Neural Causal Discovery
Mateusz Olko, Mateusz Gajewski, Joanna Wojciechowska, Mikołaj Morzy, Piotr Sankowski, Piotr Miłoś
ICML 2025
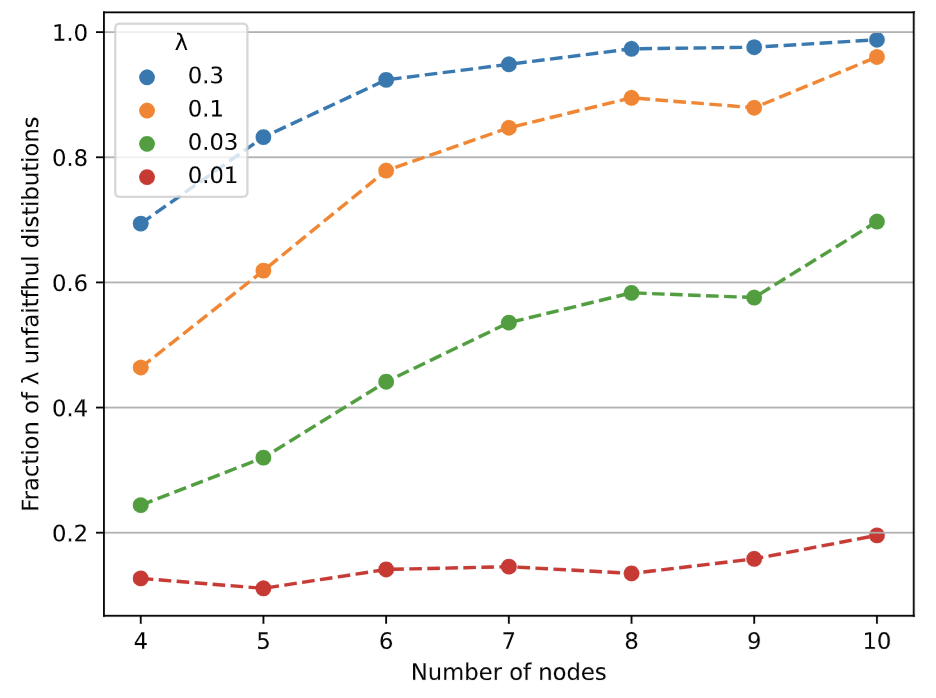
Neural causal discovery methods have recently improved in terms of scalability and computational efficiency. However, our systematic evaluation highlights significant room for improvement in their accuracy when uncovering causal structures. We identify a fundamental limitation: neural networks cannot reliably distinguish between existing and non-existing causal relationships in the finite sample regime. Our experiments reveal that neural networks, as used in contemporary causal discovery approaches, lack the precision needed to recover ground-truth graphs, even for small graphs and relatively large sample sizes. Furthermore, we identify the faithfulness property as a critical bottleneck: (i) it is likely to be violated across any reasonable dataset size range, and (ii) its violation directly undermines the performance of neural discovery methods. These findings lead us to conclude that progress within the current paradigm is fundamentally constrained, necessitating a paradigm shift in this domain.
Structured Packing in LLM Training Improves Long Context Utilization
Konrad Staniszewski, Szymon Tworkowski, Yu Zhao, Sebastian Jaszczur, Henryk Michalewski, Łukasz Kuciński, Piotr Miłoś
AAAI 2025
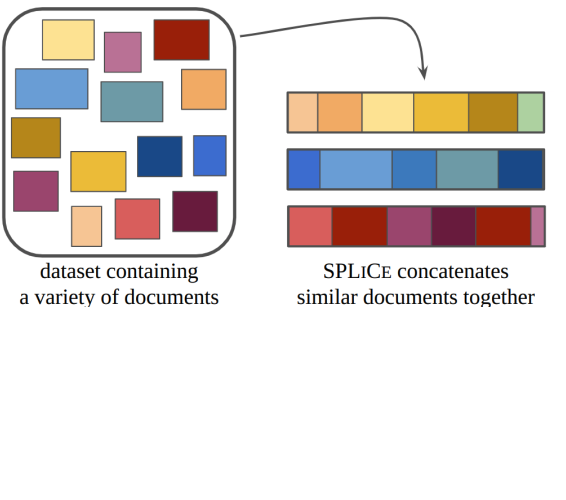
Recent developments in long-context large language models have attracted considerable attention. Yet, their real-world applications are often hindered by ineffective context information use. This work shows that structuring training data to increase semantic interdependence is an effective strategy for optimizing context utilization. To this end, we introduce Structured Packing for Long Context (SPLiCe), a method for creating training examples by using information retrieval methods to collate mutually relevant documents into a single training context. We empirically validate SPLiCe on large 3B and 7B models, showing perplexity improvements and better long-context utilization on downstream tasks. Remarkably, already relatively short fine-tuning with SPLiCe is enough to attain these benefits. Additionally, the comprehensive study of SPLiCe reveals intriguing transfer effects such as training on code data leading to perplexity improvements on text data.
Beyond Recognition: Evaluating Visual Perspective Taking in Vision Language Models
Gracjan Góral, Alicja Ziarko, Piotr Miłoś, Michał Nauman, Maciej Wołczyk, Michał Kosiński
We investigate the ability of Vision Language Models (VLMs) to perform visual perspective taking using a novel set of visual tasks inspired by established human tests. Our approach leverages carefully controlled scenes, in which a single humanoid minifigure is paired with a single object. By systematically varying spatial configurations - such as object position relative to the humanoid minifigure and the humanoid minifigure's orientation - and using both bird's-eye and surface-level views, we created 144 unique visual tasks. Each visual task is paired with a series of 7 diagnostic questions designed to assess three levels of visual cognition: scene understanding, spatial reasoning, and visual perspective taking. Our evaluation of several state-of-the-art models, including GPT-4-Turbo, GPT-4o, Llama-3.2-11B-Vision-Instruct, and variants of Claude Sonnet, reveals that while they excel in scene understanding, the performance declines significantly on spatial reasoning and further deteriorates on perspective-taking. Our analysis suggests a gap between surface-level object recognition and the deeper spatial and perspective reasoning required for complex visual tasks, pointing to the need for integrating explicit geometric representations and tailored training protocols in future VLM development.
Lightweight Latent Verifiers for Efficient Meta-Generation Strategies
Bartosz Piotrowski, Witold Drzewakowski, Konrad Staniszewski, Piotr Miłoś
Verifiers are auxiliary models that assess the correctness of outputs generated by base large language models (LLMs). They play a crucial role in many strategies for solving reasoning-intensive problems with LLMs. Typically, verifiers are LLMs themselves, often as large (or larger) than the base model they support, making them computationally expensive. In this work, we introduce a novel lightweight verification approach, LiLaVe, which reliably extracts correctness signals from the hidden states of the base LLM. A key advantage of LiLaVe is its ability to operate with only a small fraction of the computational budget required by traditional LLM-based verifiers. To demonstrate its practicality, we couple LiLaVe with popular meta-generation strategies, like best-of-n or self-consistency. Moreover, we design novel LiLaVe-based approaches, like conditional self-correction or conditional majority voting, that significantly improve both accuracy and efficiency in generation tasks with smaller LLMs. Our work demonstrates the fruitfulness of extracting latent information from the hidden states of LLMs, and opens the door to scalable and resource-efficient solutions for reasoning-intensive applications
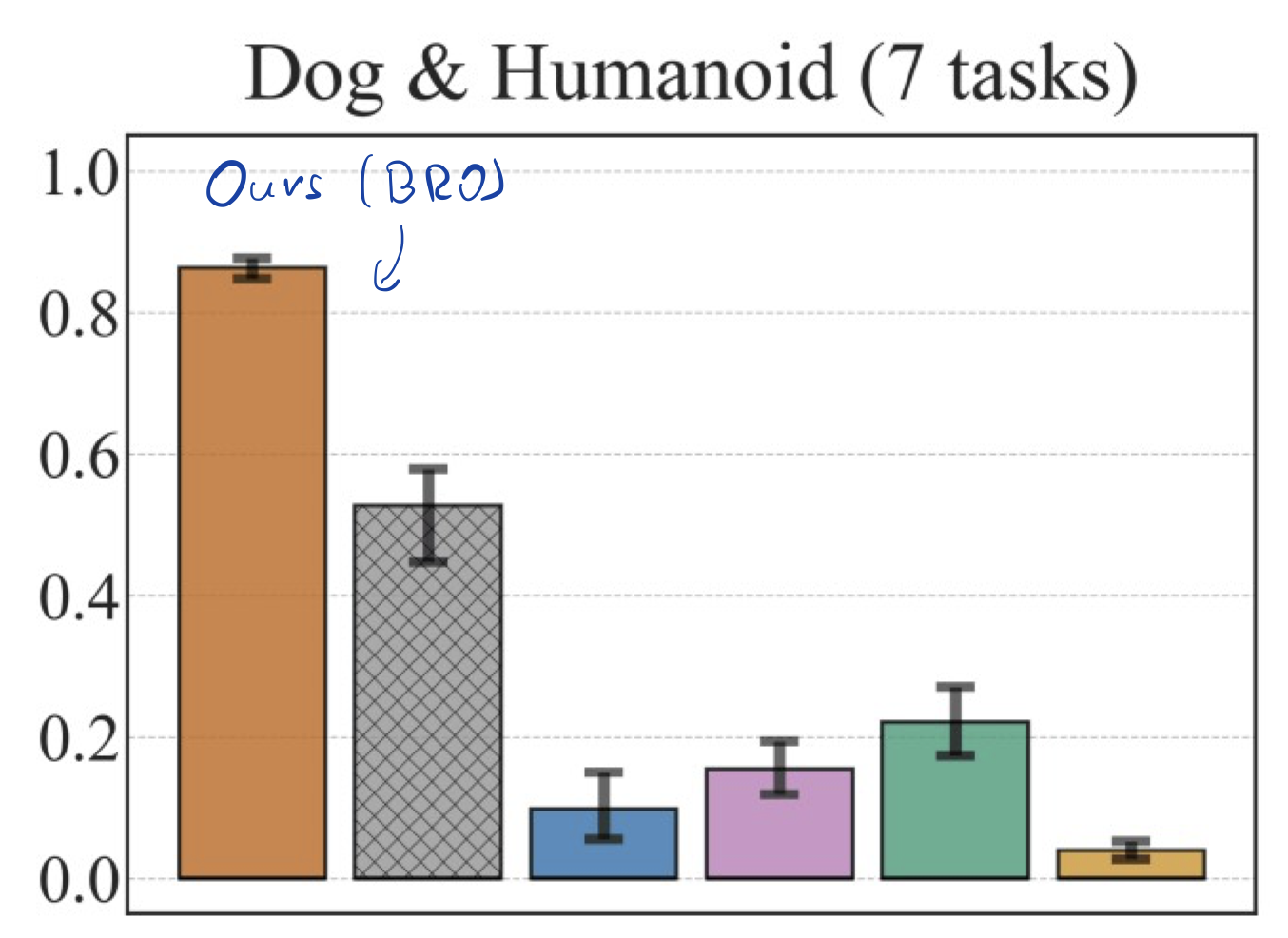
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
Michał Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miłoś, Marek Cygan
NeurIPS 2024 (spotlight)
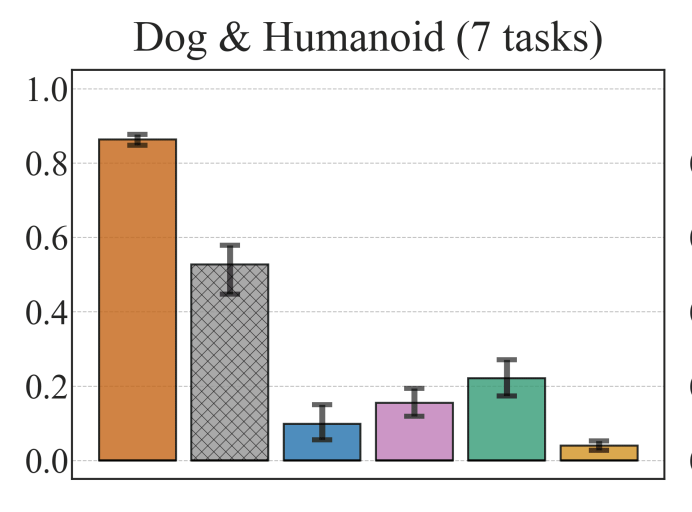
Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
Repurposing Language Models into Embedding Models: Finding the Compute-Optimal Recipe
Alicja Ziarko, Albert Q. Jiang, Bartosz Piotrowski, Wenda Li, Mateja Jamnik, Piotr Miłoś
NeurIPS 2024
Text embeddings are essential for many tasks, such as document retrieval, clustering, and semantic similarity assessment. In this paper, we study how to contrastively train text embedding models in a compute-optimal fashion, given a suite of pre-trained decoder-only language models. Our innovation is an algorithm that produces optimal configurations of model sizes, data quantities, and fine-tuning methods for text-embedding models at different computational budget levels. The resulting recipe, which we obtain through extensive experiments, can be used by practitioners to make informed design choices for their embedding models. Specifically, our findings suggest that full fine-tuning and low-rank adaptation fine-tuning produce optimal models at lower and higher computational budgets respectively.
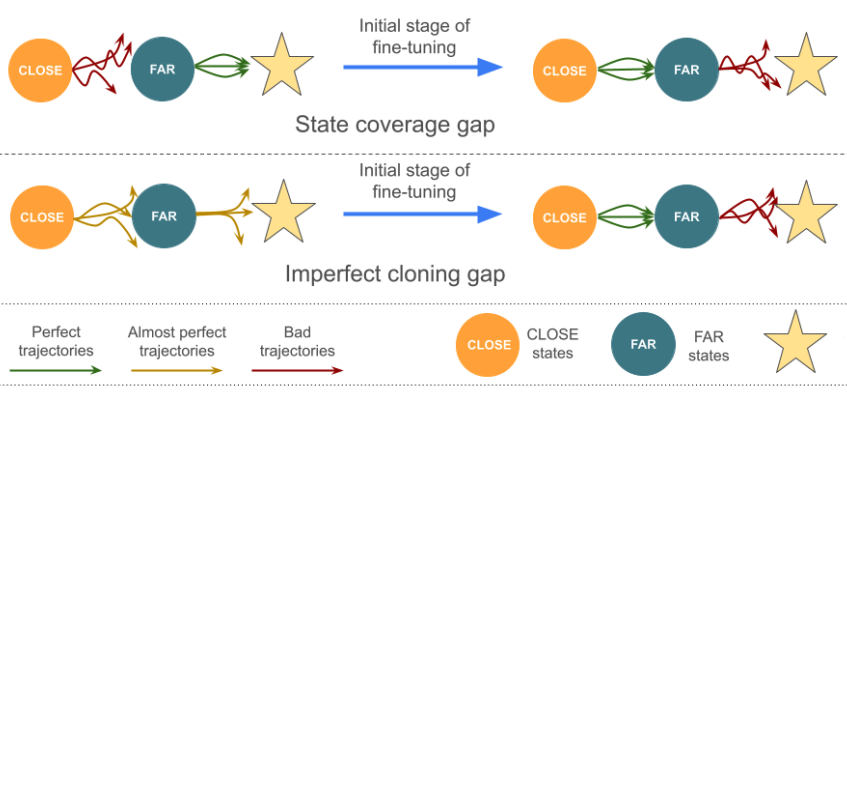
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from 5K to over 10K points in the Human Monk scenario.
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning
Michal Nauman, Michał Bortkiewicz, Mateusz Ostaszewski, Piotr Miłoś, Tomasz Trzciński, Marek Cygan
ICML 2024
Recent advancements in off-policy Reinforcement Learning (RL) have significantly improved sample efficiency, primarily due to the incorporation of various forms of regularization that enable more gradient update steps than traditional agents. However, many of these techniques have been tested in limited settings, often on tasks from single simulation benchmarks and against well-known algorithms rather than a range of regularization approaches. This limits our understanding of the specific mechanisms driving RL improvements. To address this, we implemented over 60 different off-policy agents, each integrating established regularization techniques from recent state-of-the-art algorithms. We tested these agents across 14 diverse tasks from 2 simulation benchmarks. Our findings reveal that while the effectiveness of a specific regularization setup varies with the task, certain combinations consistently demonstrate robust and superior performance. Notably, a simple Soft Actor-Critic agent, appropriately regularized, reliably solves dog tasks, which were previously solved mainly through model-based approaches.
Rafał Powalski, Bazyli Klockiewicz, Maciej Jaśkowski, Bartosz Topolski, Paweł Dąbrowski-Tumański, Maciej Wiśniewski, Łukasz Kuciński, Piotr Miłoś, Dariusz Plewczynski
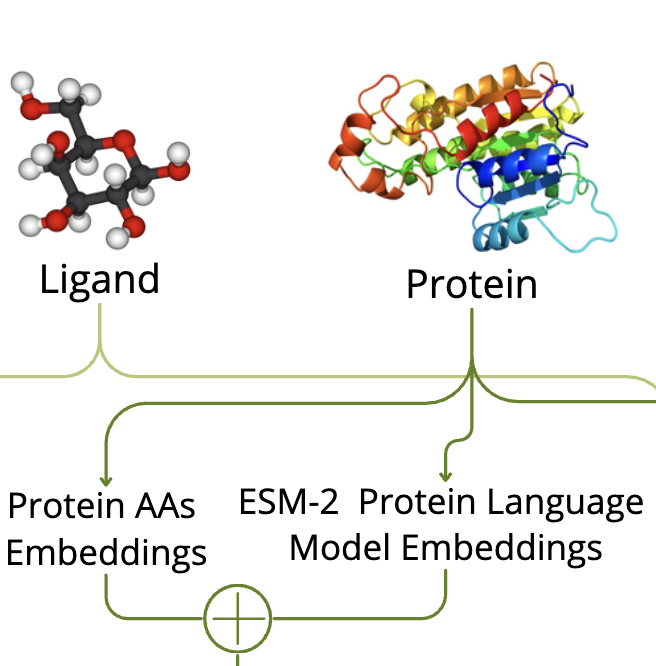
Accelerating molecular docking -- the process of predicting how molecules bind to protein targets -- could boost small-molecule drug discovery and revolutionize medicine. Unfortunately, current molecular docking tools are too slow to screen potential drugs against all relevant proteins, which often results in missed drug candidates or unexpected side effects occurring in clinical trials. To address this gap, we introduce RapidDock, an efficient transformer-based model for blind molecular docking. RapidDock achieves at least a 100× speed advantage over existing methods without compromising accuracy. On the Posebusters and DockGen benchmarks, our method achieves 52.1% and 44.0% success rates (RMSD<2Å), respectively. The average inference time is 0.04 seconds on a single GPU, highlighting RapidDock's potential for large-scale docking studies. We examine the key features of RapidDock that enable leveraging the transformer architecture for molecular docking, including the use of relative distance embeddings of 3D structures in attention matrices, pre-training on protein folding, and a custom loss function invariant to molecular symmetries.
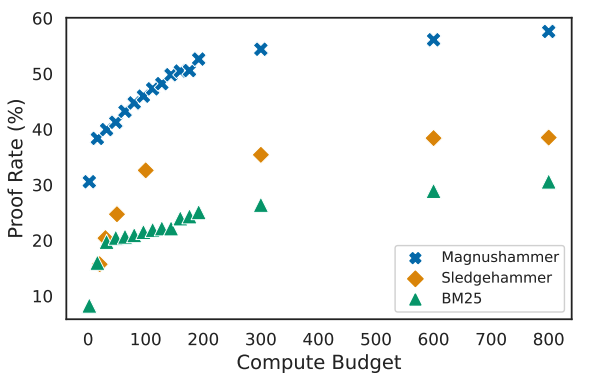
Premise selection is a fundamental problem of automated theorem proving. Previous works often use intricate symbolic methods, rely on domain knowledge, and require significant engineering effort to solve this task. In this work, we show that Magnushammer, a neural transformer-based approach, can outperform traditional symbolic systems by a large margin. Tested on the PISA benchmark, Magnushammer achieves 59.5% proof rate compared to a 38.3% proof rate of Sledgehammer, the most mature and popular symbolic-based solver. Furthermore, by combining Magnushammer with a neural formal prover based on a language model, we significantly improve the previous state-of-the-art proof rate from 57.0% to 71.0%.
Analysing The Impact of Sequence Composition on Language Model Pre-Training
Yu Zhao, Yuanbin Qu, Konrad Staniszewski, Szymon Tworkowski, Wei Liu, Piotr Miłoś, Yuxiang Wu, Pasquale Minervini
ACL 2024
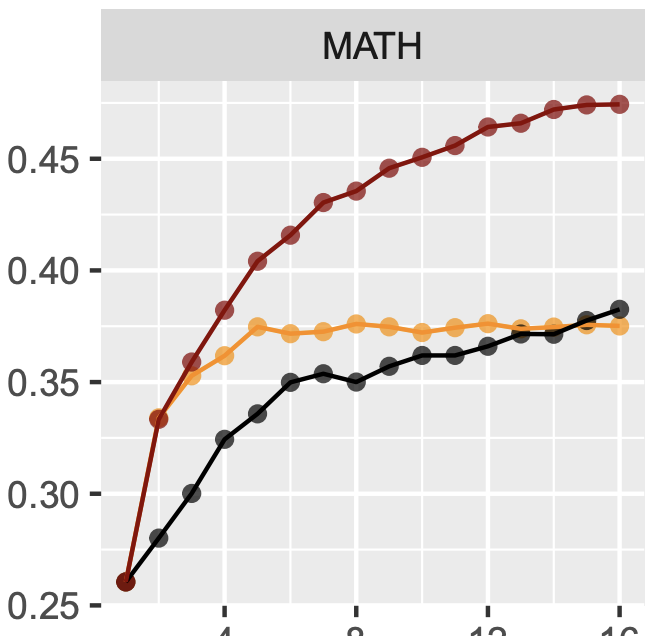
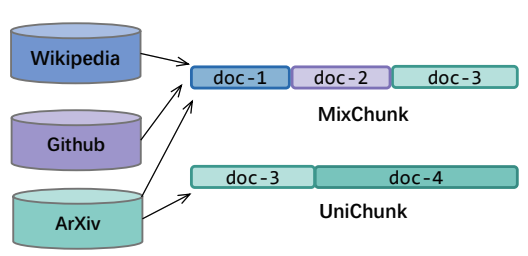
Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy is widely adopted due to its simplicity and efficiency. However, to this day, the influence of the pre-training sequence composition strategy on the generalisation properties of the model remains under-explored. In this work, we find that applying causal masking can lead to the inclusion of distracting information from previous documents during pre-training, which negatively impacts the performance of the models on language modelling and downstream tasks. In intra-document causal masking, the likelihood of each token is only conditioned on the previous tokens in the same document, eliminating potential distracting information from previous documents and significantly improving performance. Furthermore, we find that concatenating related documents can reduce some potential distractions during pre-training, and our proposed efficient retrieval-based sequence construction method, BM25Chunk, can improve in-context learning ($+11.6\%$), knowledge memorisation ($+9.8\%$), and context utilisation ($+7.2\%$) abilities of language models without sacrificing efficiency.
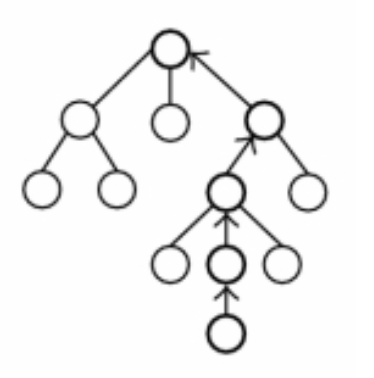
What Matters in Hierarchical Search for Combinatorial Reasoning Problems?
Michał Zawalski, Gracjan Góral, Michał Tyrolski, Emilia Wiśnios, Franciszek Budrowski, Łukasz Kuciński, Piotr Miłoś
Efficiently tackling combinatorial reasoning problems, particularly the notorious NP-hard tasks, remains a significant challenge for AI research. Recent efforts have sought to enhance planning by incorporating hierarchical high-level search strategies, known as subgoal methods. While promising, their performance against traditional low-level planners is inconsistent, raising questions about their application contexts. In this study, we conduct an in-depth exploration of subgoal-planning methods for combinatorial reasoning. We identify the attributes pivotal for leveraging the advantages of high-level search: hard-to-learn value functions, complex action spaces, presence of dead ends in the environment, or using data collected from diverse experts. We propose a consistent evaluation methodology to achieve meaningful comparisons between methods and reevaluate the state-of-the-art algorithms.
Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue is to endow an attention layer with access to an external memory, which comprises of (key, value) pairs. Yet, as the number of documents increases, the proportion of relevant keys to irrelevant ones decreases, leading the model to focus more on the irrelevant keys. We identify a significant challenge, dubbed the distraction issue, where keys linked to different semantic values might overlap, making them hard to distinguish. To tackle this problem, we introduce the Focused Transformer (FoT), a technique that employs a training process inspired by contrastive learning. This novel approach enhances the structure of the (key, value) space, enabling an extension of the context length. Our method allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. This is demonstrated by our fine-tuning of 3B and 7B OpenLLaMA checkpoints. The resulting models, which we name LongLLaMA, exhibit advancements in tasks requiring a long context. We further illustrate that our LongLLaMA models adeptly manage a 256k context length for passkey retrieval.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
Maciej Pióro, Kamil Ciebiera, Krystian Król, Jan Ludziejewski, Michał Krutul, Jakub Krajewski, Szymon Antoniak, Piotr Miłoś, Marek Cygan, Sebastian Jaszczur
Workshop on Understanding of Foundation Models, ICLR 2024
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based Large Language Models, including recent state-of-the-art open models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable performance. Our model, MoE-Mamba, outperforms both Mamba and baseline Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.35× fewer training steps while preserving the inference performance gains of Mamba against Transformer.
The Tunnel Effect: Building Data Representations in Deep Neural Networks
Wojciech Masarczyk, Mateusz Ostaszewski, Ehsan Imani, Razvan Pascanu, Piotr Miłoś, Tomasz Trzciński
NeurIPS 2023
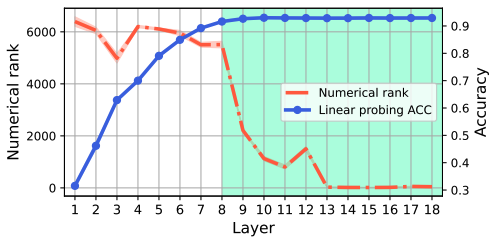
Deep neural networks are widely known for their remarkable effectiveness across various tasks, with the consensus that deeper networks implicitly learn more complex data representations. This paper shows that sufficiently deep networks trained for supervised image classification split into two distinct parts that contribute to the resulting data representations differently. The initial layers create linearly-separable representations, while the subsequent layers, which we refer to as extit{the tunnel}, compress these representations and have a minimal impact on the overall performance. We explore the tunnel's behavior through comprehensive empirical studies, highlighting that it emerges early in the training process. Its depth depends on the relation between the network's capacity and task complexity. Furthermore, we show that the tunnel degrades out-of-distribution generalization and discuss its implications for continual learning.
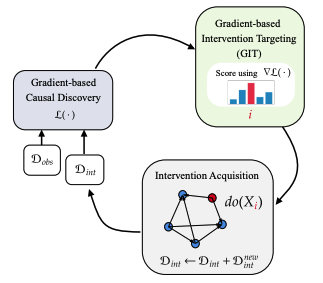
Inferring causal structure from data is a challenging task of fundamental importance in science. Observational data are often insufficient to identify a system's causal structure uniquely. While conducting interventions (i.e., experiments) can improve the identifiability, such samples are usually challenging and expensive to obtain. Hence, experimental design approaches for causal discovery aim to minimize the number of interventions by estimating the most informative intervention target. In this work, we propose a novel Gradient-based Intervention Targeting method, abbreviated GIT, that 'trusts' the gradient estimator of a gradient-based causal discovery framework to provide signals for the intervention acquisition function. We provide extensive experiments in simulated and real-world datasets and demonstrate that GIT performs on par with competitive baselines, surpassing them in the low-data regime
𝚝𝚜𝙶𝚃: Stochastic Time Series Modeling With Transformer
Łukasz Kuciński, Witold Drzewakowski, Mateusz Olko, Piotr Kozakowski, Łukasz Maziarka, Marta Emilia Nowakowska, Łukasz Kaiser, Piotr Miłoś
Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing 𝚝𝚜𝙶𝚃, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that 𝚝𝚜𝙶𝚃 outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of 𝚝𝚜𝙶𝚃's ability to model the data distribution and predict marginal quantile values.
Complex reasoning problems contain states that vary in the computational cost required to determine a good action plan. Taking advantage of this property, we propose Adaptive Subgoal Search (AdaSubS), a search method that adaptively adjusts the planning horizon. To this end, AdaSubS generates diverse sets of subgoals at different distances. A verification mechanism is employed to filter out unreachable subgoals swiftly and thus allowing to focus on feasible further subgoals. In this way, AdaSubS benefits from the efficiency of planning with longer subgoals and the fine control with the shorter ones. We show that AdaSubS significantly surpasses hierarchical planning algorithms on three complex reasoning tasks: Sokoban, the Rubik's Cube, and inequality proving benchmark INT, setting new state-of-the-art on INT.
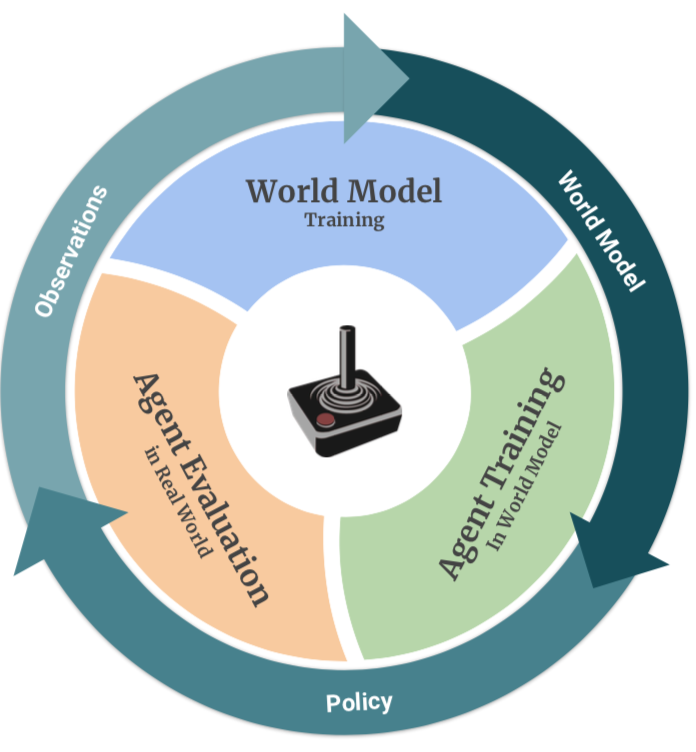
The Effectiveness of World Models for Continual Reinforcement Learning
Samuel Kessler, Mateusz Ostaszewski, Michał Bortkiewicz, Mateusz Żarski, Maciej Wołczyk, Jack Parker-Holder, Stephen J. Roberts, Piotr Miłoś
CoLLAs 2023
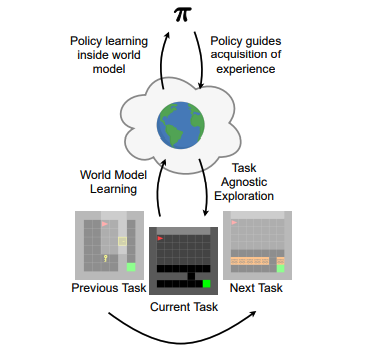
World models power some of the most efficient reinforcement learning algorithms. In this work, we showcase that they can be harnessed for continual learning - a situation when the agent faces changing environments. World models typically employ a replay buffer for training, which can be naturally extended to continual learning. We systematically study how different selective experience replay methods affect performance, forgetting, and transfer. We also provide recommendations regarding various modeling options for using world models. The best set of choices is called Continual-Dreamer, it is task-agnostic and utilizes the world model for continual exploration. Continual-Dreamer is sample efficient and outperforms state-of-the-art task-agnostic continual reinforcement learning methods on Minigrid and Minihack benchmarks.
Michał Zając, Kamil Deja, Anna Kuzina, Jakub M. Tomczak, Tomasz Trzciński, Florian Shkurti, Piotr Miłoś
Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
Disentangling Transfer in Continual Reinforcement Learning
Maciej Wołczyk, Michał Zając, Razvan Pascanu, Łukasz Kuciński, Piotr Miłoś
NeurIPS 2022
The ability of continual learning systems to transfer knowledge from previously seen tasks in order to maximize performance on new tasks is a significant challenge for the field, limiting the applicability of continual learning solutions to realistic scenarios. Consequently, this study aims to broaden our understanding of transfer and its driving forces in the specific case of continual reinforcement learning. We adopt SAC as the underlying RL algorithm and Continual World as a suite
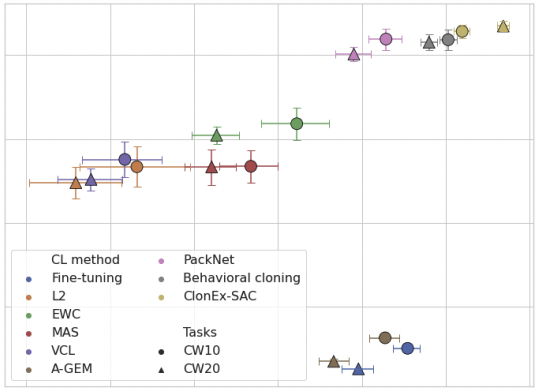
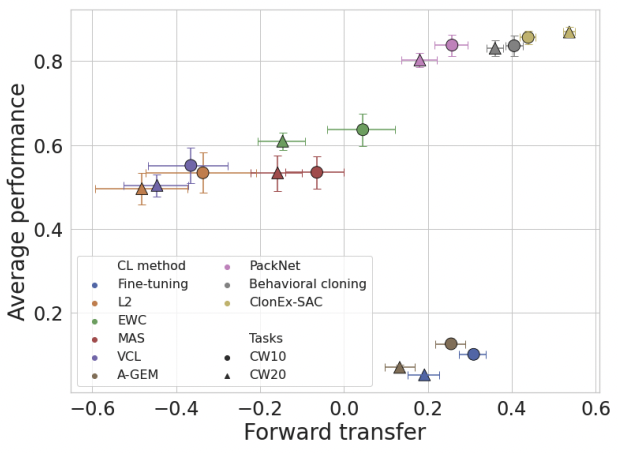
of continuous control tasks. We systematically study how different components of SAC (the actor and the critic, exploration, and data) affect transfer efficacy, and we provide recommendations regarding various modeling options. The best set of choices, dubbed ClonEx-SAC, is evaluated on the recent Continual World benchmark. ClonEx-SAC achieves 87% final success rate compared to 80% of PackNet, the best method in the benchmark. Moreover, the transfer grows from 0.18 to 0.54 according to the metric provided by Continual World.
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers
Albert Q. Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu, Mateja Jamnik
NeurIPS 2022
In theorem proving, the task of selecting useful premises from a large library to unlock the proof of a given conjecture is crucially important. This presents a challenge for all theorem provers, especially the ones based on language models, due to their relative inability to reason over huge volumes of premises in text form. This paper introduces Thor, a framework integrating language models and automated theorem provers to overcome this difficulty. In Thor, a class of methods called hammers that leverage the power of automated theorem provers are used for premise selection, while all other tasks are designated to language models. Thor increases a language model's success rate on the PISA dataset from 39% to 57%, while solving 8.2% of problems neither language models nor automated theorem provers are able to solve on their own. Furthermore, with a significantly smaller computational budget, Thor can achieve a success rate on the MiniF2F dataset that is on par with the best existing methods. Thor can be instantiated for the majority of popular interactive theorem provers via a straightforward protocol we provide.
Szymon Tworkowski, Maciej Mikuła, Tomasz Odrzygóźdź, Konrad Czechowski, Szymon Antoniak, Albert Jiang, Christian Szegedy, Łukasz Kuciński, Piotr Miłoś and Yuhuai Wu
AITP 2022
Premise selection, the problem of selecting a useful premise to prove a new theorem, is an essential part of theorem proving. Existing language models cannot access knowledge beyond a small context window, and therefore are unsatisfactory at retrieving useful premises (i.e., premise selection) from large databases for theorem proving. In this work, we provide a solution to this problem, by combining a premise selection model with a language model. We first select a handful (e.g., $8$) of premises from a large theorem database consisting of $100K$ premises, and present them in the context along with proof states. The language model then utilizes these premises to construct a proof step. We show that this retrieval-augmented prover achieves significant improvements in proof rates compared to the language model alone.
Humans excel in solving complex reasoning tasks through a mental process of moving from one idea to a related one. Inspired by this, we propose Subgoal Search (kSubS) method. Its key component is a learned subgoal generator that produces a diversity of subgoals that are both achievable and closer to the solution. Using subgoals reduces the search space and induces a high-level search graph suitable for efficient planning. In this paper, we implement kSubS using a transformer-based subgoal module coupled with the classical best-first search framework. We show that a simple approach of generating k-th step ahead subgoals is surprisingly efficient on three challenging domains: two popular puzzle games, Sokoban and the Rubik's Cube, and an inequality proving benchmark INT. kSubS achieves strong results including state-of-the-art on INT within a modest computational budget.
Continual World: A Robotic Benchmark For Continual Reinforcement Learning
Maciej Wołczyk, Michał Zając, Razvan Pascanu, Łukasz Kuciński, Piotr Miłoś
NeurIPS 2021
Continual learning (CL) -- the ability to continuously learn, building on previously acquired knowledge -- is a natural requirement for long-lived autonomous reinforcement learning (RL) agents. While building such agents, one needs to balance opposing desiderata, such as constraints on capacity and compute, the ability to not catastrophically forget, and to exhibit positive transfer on new tasks. Understanding the right trade-off is conceptually and computationally challenging, which we argue has led the community to overly focus on catastrophic forgetting. In response to these issues, we advocate for the need to prioritize forward transfer and propose Continual World, a benchmark consisting of realistic and meaningfully diverse robotic tasks built on top of Meta-World as a testbed. Following an in-depth empirical evaluation of existing CL methods, we pinpoint their limitations and highlight unique algorithmic challenges in the RL setting. Our benchmark aims to provide a meaningful and computationally inexpensive challenge for the community and thus help better understand the performance of existing and future solutions.
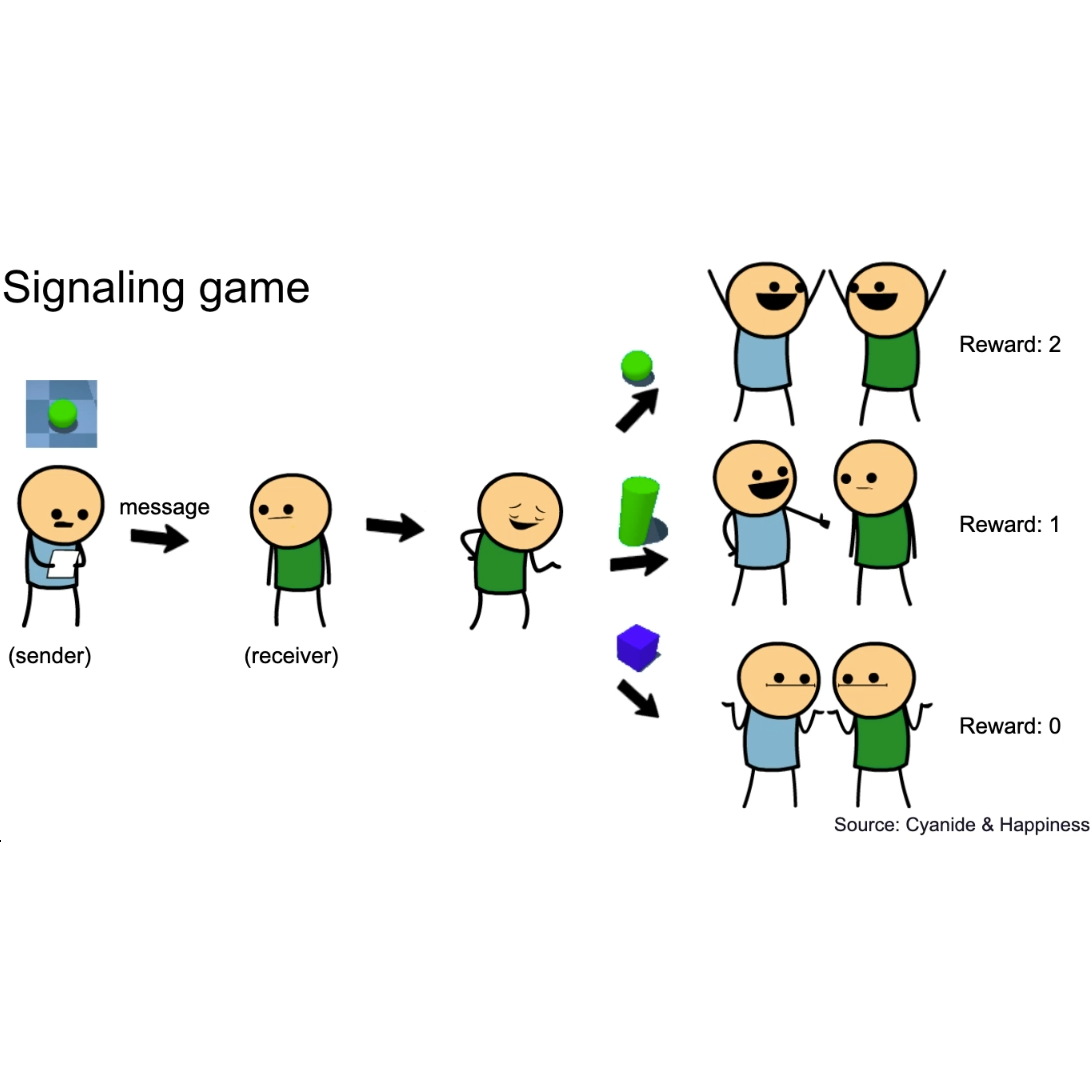
Catalytic Role Of Noise And Necessity Of Inductive Biases In The Emergence Of Compositional Communication
Łukasz Kuciński, Tomasz Korbak, Paweł Kołodziej, Piotr Miłoś
NeurIPS 2021
Communication is compositional if complex signals can be represented as a combination of simpler subparts. In this paper, we theoretically show that inductive biases on both the training framework and the data are needed to develop a compositional communication. Moreover, we prove that compositionality spontaneously arises in the signaling games, where agents communicate over a \emph{noisy channel}. We experimentally confirm that a range of noise levels, which depends on the model and the data, indeed promotes compositionality. Finally, we provide a comprehensive study of this dependence and report results in terms of recently studied compositionality metrics: topographical similarity, conflict count, and context independence.
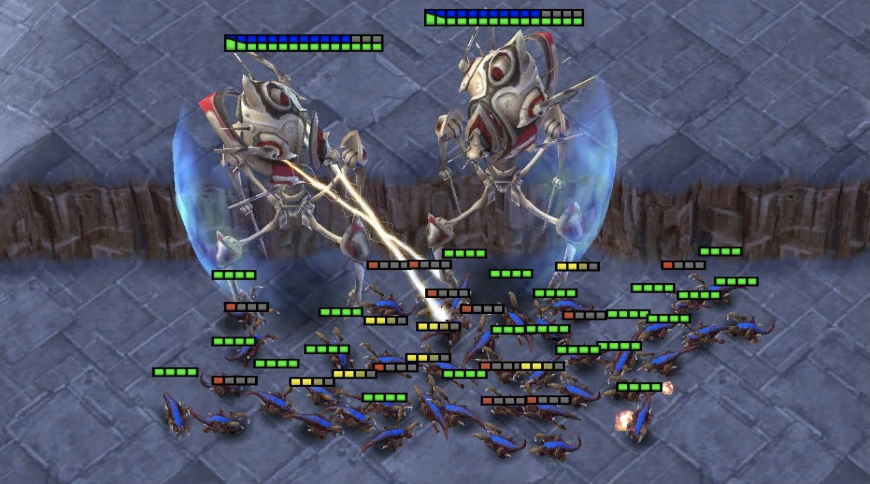
Off-Policy Correction For Multi-Agent Reinforcement Learning
Michał Zawalski, Błażej Osiński, Henryk Michalewski, Piotr Miłoś
AAMAS 2022 (extended abstract), NeurIPS Deep RL workshop 2021
Multi-agent reinforcement learning (MARL) provides a framework for problems involving multiple interacting agents. Despite apparent similarity to the single-agent case, multi-agent problems are often harder to train and analyze theoretically. In this work, we propose MA-Trace, a new on-policy actor-critic algorithm, which extends V-Trace to the MARL setting. The key advantage of our algorithm is its high scalability in a multi-worker setting. To this end, MA-Trace utilizes importance sampling as an off-policy correction method, which allows distributing the computations with no impact on the quality of training. Furthermore, our algorithm is theoretically grounded -- we prove a fixed-point theorem that guarantees convergence. We evaluate the algorithm extensively on the StarCraft Multi-Agent Challenge, a standard benchmark for multi-agent algorithms. MA-Trace achieves high performance on all its tasks and exceeds state-of-the-art results on some of them.
Continuous Control With Ensemble Deep Deterministic Policy Gradients
Piotr Januszewski, Mateusz Olko, Michał Królikowski, Jakub Swiatkowski, Marcin Andrychowicz, Łukasz Kuciński, Piotr Miłoś
NeurIPS Deep RL workshop 2021
The growth of deep reinforcement learning (RL) has brought multiple exciting tools and methods to the field. This rapid expansion makes it important to understand the interplay between individual elements of the RL toolbox. We approach this task from an empirical perspective by conducting a study in the continuous control setting. We present multiple insights of fundamental nature, including: a commonly used additive action noise is not required for effective exploration and can even hinder training; the performance of policies trained using existing methods varies significantly across training runs, epochs of training, and evaluation runs; the critics' initialization plays the major role in ensemble-based actor-critic exploration, while the training is mostly invariant to the actors' initialization; a strategy based on posterior sampling explores better than the approximated UCB combined with the weighted Bellman backup; the weighted Bellman backup alone cannot replace the clipped double Q-Learning. As a conclusion, we show how existing tools can be brought together in a novel way, giving rise to the Ensemble Deep Deterministic Policy Gradients (ED2) method, to yield state-of-the-art results on continuous control tasks from \mbox{OpenAI Gym MuJoCo}. From the practical side, ED2 is conceptually straightforward, easy to code, and does not require knowledge outside of the existing RL toolbox.
Robust and Efficient Planning using Adaptive Entropy Tree Search
Piotr Kozakowski, Mikołaj Pacek, Piotr Miłoś
IJCNN 2022
In this paper, we present the Adaptive EntropyTree Search (ANTS) algorithm. ANTS builds on recent successes of maximum entropy planning while mitigating its arguably major drawback - sensitivity to the temperature setting. We endow ANTS with a mechanism, which adapts the temperature to match a given range of action selection entropy in the nodes of the planning tree. With this mechanism, the ANTS planner enjoys remarkable hyper-parameter robustness, achieves high scores on the Atari benchmark, and is a capable component of a planning-learning loop akin to AlphaZero. We believe that all these features make ANTS a compelling choice for a general planner for complex tasks.
CARLA Real Traffic Scenarios -- novel training ground and benchmark for autonomous driving
Błażej Osiński, Piotr Miłoś, Adam Jakubowski, Paweł Zięcina, Michał Martyniak, Christopher Galias, Antonia Breuer, Silviu Homoceanu, Henryk Michalewski
Autonomous Driving Workshop NeurIPS 2020
This work introduces interactive traffic scenarios in the CARLA simulator, which are based on real-world traffic. We concentrate on tactical tasks lasting several seconds, which are especially challenging for current control methods. The CARLA Real Traffic Scenarios (CRTS) is intended to be a training and testing ground for autonomous driving systems. To this end, we open-source the code under a permissive license and present a set of baseline policies. CRTS combines the realism of traffic scenarios and the flexibility of simulation. We use it to train agents using a reinforcement learning algorithm. We show how to obtain competitive polices and evaluate experimentally how observation types and reward schemes affect the training process and the resulting agent's behavior.
Trust, but verify: model-based exploration in sparse reward environments
Konrad Czechowski, Tomasz Odrzygóźdź, Michał Izworski, Marek Zbysiński, Łukasz Kuciński, Piotr Miłoś
IJCNN 2021, DRL Workshop, NeurIPS 2020
Planning in large state spaces inevitably needs to balance depth and breadth of the search. It has a crucial impact on their performance and most planners manage this
interplay implicitly. We present a novel method Shoot Tree Search (STS), which makes it possible to control this trade-off more explicitly. Our algorithm can be
understood as an interpolation between two celebrated search mechanisms: MCTS and random shooting. It also lets the user control the bias-variance trade-off, akin to $TD(n)$, but in the tree search context.
In experiments on challenging domains, we show that STS can get the best of both worlds consistently achieving higher scores.
Structure and randomness in planning and reinforcement learning
Piotr Januszewski, Konrad Czechowski, Piotr Kozakowski, Łukasz Kuciński, Piotr Miłoś
IJCNN 2021, DRL Workshop, NeurIPS 2020
Planning in large state spaces inevitably needs to balance depth and breadth of the search. It has a crucial impact on their performance and most planners manage this
interplay implicitly. We present a novel method Shoot Tree Search (STS), which makes it possible to control this trade-off more explicitly. Our algorithm can be
understood as an interpolation between two celebrated search mechanisms: MCTS and random shooting. It also lets the user control the bias-variance trade-off, akin to $TD(n)$, but in the tree search context.
In experiments on challenging domains, we show that STS can get the best of both worlds consistently achieving higher scores.
Łukasz Kaiser, Mohammad Babaeizadeh, Piotr Miłoś, Błażej Osiński, Roy H. Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Ryan Sepassi, George Tucker, Henryk Michalewski
ICLR 2020 (spotlight), also Generative Modeling and Model-Based Reasoning for Robotics and AI Workshop, ICML 2019
Our work advances the state-of-the-art in model-based reinforcement learning by introducing a system that, to our knowledge, is the first to successfully handle a variety of challenging games in the ALE benchmark. To that end, we experiment with several stochastic video prediction techniques, including a novel model based on discrete latent variables. We also present an approach, called Simulated Policy Learning (SimPLe), that utilizes these video prediction techniques and can train a policy to play the game within the learned model. With several iterations of dataset aggregation, where the policy is deployed to collect more data in the original game, we can learn a policy that, for many games, can successfully play the game in the real environment (see videos on the project webpage).
In our empirical evaluation, we find that SimPLe is significantly more sample-efficient than a highly tuned version of the state-of-the-art Rainbow algorithm on almost all games. In particular, in low data regime of $100$k samples, on more than half of the games, our method achieves a score which Rainbow requires at least twice as many samples. In the best case of Freeway, our method is more than $10x$ more sample-efficient.
Uncertainty-sensitive Learning and Planning with Ensembles
Piotr Miłoś, Łukasz Kuciński, Konrad Czechowski, Piotr Kozakowski, Maciek Klimek
Uncertainty and Robustness in Deep Learning Workshop, ICML 2020
We propose a reinforcement learning framework for discrete environments in which an agent makes both strategic and tactical decisions. The former manifests itself through the use of value function, while the latter is powered by a tree search planner. These tools complement each other. The planning
module performs a local what-if analysis, which allows to avoid tactical
pitfalls and boost backups of the value function. The value function, being
global in nature, compensates for inherent locality of the planner. In order
to further solidify this synergy, we introduce an exploration mechanism with
two distinctive components: uncertainty modelling and risk measurement.
To model the uncertainty we use value function ensembles, and to reflect
risk we use propose several functionals that summarize the implied by the
ensemble. We show that our method performs well on hard exploration
environments: Deep-sea, toy Montezuma’s Revenge, and Sokoban. In all
the cases, we obtain speed-up in learning and boost in performance.
Simulation-based reinforcement learning for real-world autonomous driving
Błażej Osiński, Adam Jakubowski, Paweł Zięcina, Piotr Miłoś, Christopher Galias, Silviu Homoceanu, Henryk Michalewski
ICRA 2020 also NeurIPS 2019, Autonomous Driving Workshop
We use synthetic data and a reinforcement learning algorithm to train a driving system controlling a full-size real-world vehicle in a number of restricted driving scenarios. The driving policy uses RGB images as input.
We show how design decisions about perception, control and training impact the real-world performance.
Developmentally motivated emergence of compositional communication via template transfer
Tomasz Korbak, Julian Zubek, Łukasz Kuciński, Piotr Miłoś, Joanna R̨aczaszek-Leonardi
NeurIPS 2019, Emergent Communication: Towards Natural Language Workshop
This paper explores a novel approach to achieving emergent compositional communication in multi-agent systems. We propose a training regime implementing template transfer, the idea of carrying over learned biases across contexts. In our method, a sender--receiver pair is first trained with disentangled loss functions and then the receiver is transferred to train a new sender with a standard loss. Unlike other methods (e.g. the obverter algorithm), our approach does not require imposing inductive biases on the architecture of the agents. We experimentally show the emergence of compositional communication using topographical similarity, zero-shot generalization and context independence as evaluation metrics. The presented approach is connected to an important line of work in semiotics and developmental psycholinguistics: it supports a conjecture that compositional communication is scaffolded on simpler communication protocols.
Expert-augmented actor-critic for ViZDoom and Montezumas Revenge
Henryk Michalewski, Michał Gramulewicz, Piotr Miłoś
Deep RL Workshop NeurIPS 2018
We propose an expert-augmented actor-critic algorithm, which we evaluate on two environments with sparse rewards: Montezumas Revenge and a demanding maze from the ViZDoom suite. In the case of Montezumas Revenge, an agent trained with our method achieves very good results consistently scoring above 27,000 points (in many experiments beating the first world). With an appropriate choice of hyperparameters, our algorithm surpasses the performance of the expert data. In a number of experiments, we have observed an unreported bug in Montezumas Revenge which allowed the agent to score more than 800,000 points.
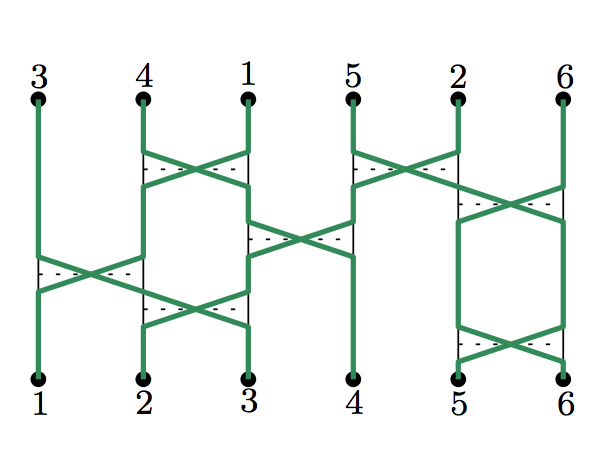
The interchange process with reversals on the complete graph
Jakob E. Björnberg, Michał Kotowski, Benjamin Lees, Piotr Miłoś
Electronic Journal of Probability, 24, 2019
We consider an extension of the interchange process on the complete graph, in which a fraction of the transpositions are replaced by `reversals'. The model is motivated by statistical physics, where it plays a role in stochastic representations of $XXZ$-models. We prove convergence to $PD(1/2)$ of the rescaled cycle sizes, above the critical point for the appearance of macroscopic cycles. This extends a result of Schramm on convergence to $PD(1)$ for the usual interchange process.
Phase transition for the interchange and quantum Heisenberg models on the Hamming graph
Radosław Adamczak, Michał Kotowski, Piotr Miłoś
Ann. Inst. H. Poincare Probab. Statist. 57, 2021
We study a family of random permutation models on the $2$-dimensional Hamming graph $H(2,n)$, containing the interchange process and the cycle-weighted interchange process with parameter $\theta>0$. This family contains the random representation of the quantum Heisenberg ferromagnet. We show that in these models the cycle structure of permutations undergoes a phase transition -- when the number of transpositions defining the permutation is $\leq cn2$, for small enough $c>0$, all cycles are microscopic, while for more than $\geq Cn^2$ transpositions, for large enough $C>0$, macroscopic cycles emerge with high probability.
We provide bounds on values $C,c$ depending on the parameter $\theta$ of the model, in particular for the interchange process we pinpoint exactly the critical time of the phase transition. Our results imply also the existence of a phase transition in the quantum Heisenberg ferromagnet on $H(2,n)$, namely for low enough temperatures spontaneous magnetization occurs, while it is not the case for high temperatures.
At the core of our approach is a novel application of the cyclic random walk, which might be of independent interest. By analyzing explorations of the cyclic random walk, we show that sufficiently long cycles of a random permutation are uniformly spread on the graph, which makes it possible to compare our models to the mean-field case, i.e., the interchange process on the complete graph, extending the approach used earlier by Schramm.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments. Proximal Policy Optimization with Policy Blending
Henryk Michalewski, Piotr Miłoś, Błażej Osiński
NIPS 2017 Learning to Run challenge (6th place)
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.
CLT for supercritical branching processes with heavy-tailed branching law
Rafał Marks, Piotr Miłoś
Consider a branching system with particles moving according to an Ornstein-Uhlenbeck process with drift $\mu>0$ and branching according to a law in the domain of attraction of the $(1+\beta)$-stable distribution. The mean of the branching law is strictly larger than $1$ implying that the system is supercritical and the total number of particles grows exponentially at some rate $\lambda>0$.
It is known that the system obeys a law of large numbers. In the paper we study its rate of convergence.
We discover an interesting interplay between the branching rate $\lambda$ and the drift parameter $\mu$. There are three regimes of the second order behavior:
⋅ small branching, $\lambda<(1+1/\beta)$, then the speed of convergence is the same as in the stable central limit theorem but the limit is affected by the dependence between particles.
⋅ critical branching, $\lambda=(1+1/\beta)$, then the dependence becomes strong enough to make the rate of convergence slightly smaller, yet the qualitative behaviour still resembles the stable central limit theorem
⋅ large branching, $\lambda>(1+1/\beta)$, then the dependence manifests much more profoundly, the rate of convergence is substantially smaller and strangely the limit holds a.s.
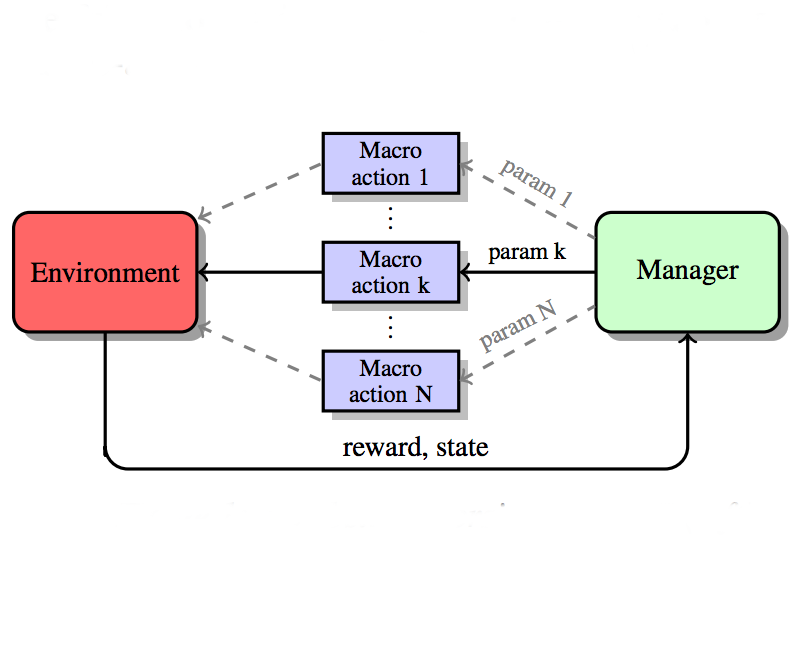
Hierarchical Reinforcement Learning with Parameters
Maciej Klimek, Henryk Michalewski, Piotr Miłoś
Proceedings of the 1st Annual Conference on Robot Learning, PMLR 78, 2017
In this work we introduce and evaluate a model of Hierarchical Reinforcement Learning with Parameters. In the first stage we train agents to execute relatively simple actions like reaching or gripping. In the second stage we train a hierarchical manager to compose these actions to solve more complicated tasks. The manager may pass parameters to agents thus controlling details of undertaken
actions. The hierarchical approach with parameters can be used with any optimization algorithm.
In this work we adapt to our setting methods described in Trust Region Policy Optimization. We show that their theoretical foundation, including monotonicity of improvements, still holds. We experimentally compare the hierarchical reinforcement learning with the standard, non-hierarchical approach and conclude that the hierarchical learning with parameters is a viable way to improve final results and stability of learning.
Existence of a phase transition of the interchange process on the Hamming graph
Piotr Miłoś, Batı Şengül
Electronic Journal of Probability 24, 2019
The interchange process on a finite graph is obtained by placing a particle on each vertex of the graph, then at rate $1$, selecting an edge uniformly at random and swapping the two particles at either end of this edge. In this paper we develop new techniques to show the existence of a phase transition of the interchange process on the $2$-dimensional Hamming graph. We show that in the subcritical phase, all of the cycles of the process have length $O(\log n)$, whereas in the supercritical phase a positive density of vertices lie in cycles of length at least $n^{2-\epsilon}$ for any $\epsilon>0$.
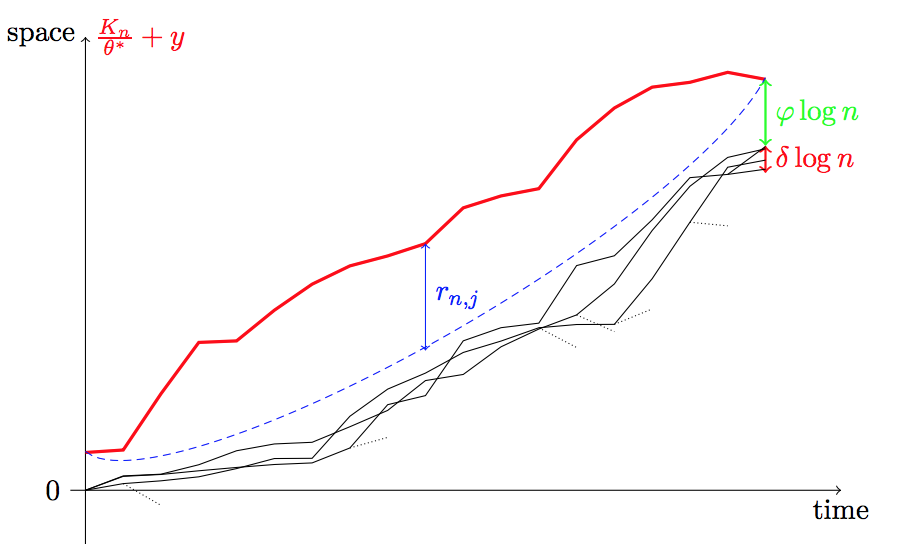
Maximal displacement of a supercritical branching random walk in a time-inhomogeneous random environment
Bastien Mallein, Piotr Miłoś
Stoch. Proc. Appli. 129, 2019
The behavior of the maximal displacement of a supercritical branching random walk has been a subject of intense studies for a long time. But only recently the case of time-inhomogeneous branching has gained focus. The contribution of this paper is to analyze a time-inhomogeneous model with two levels of randomness. In the first step a sequence of branching laws is sampled independently according to a distribution on the set of point measures' laws. Conditionally on the realization of this sequence (called environment) we define a branching random walk and find the asymptotic behavior of its maximal particle. It is of the form $V_n-\varphi \log n + o_{\mathbf{P}}(\log n)$, where $V_n$ is a function of the environment that behaves as a random walk and $\varphi>0$ is a deterministic constant, which turns out to be bigger than the usual logarithmic correction of the homogeneous branching random walk.
Ready to start an exciting ML project? I am constantly looking for postdocs, Ph.D. and master students. Practical info for students.
Visualization of MCTS tree in game of Splendor, by T. Odrzygóźdź. Occupation heatmap in Montezuma's Revenge. Student project by Ł. Krystoń. See full game.
Let's Get In Touch!
Send me an email and I'll get back to you as soon as possible!
 We are hiring.
We are hiring. 

 UCL Dark seminar!
UCL Dark seminar!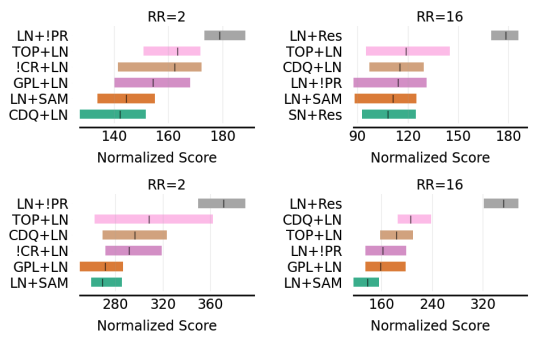
















{kind=link}
{kind=link}