Tuż po wyborach samorządowych pojawiło się wiele wizualizacji, które pokazywały wyniki i przebieg wyborów. Moją uwagę szczególnie przyciągnęły opracowania przygotwane przez Wojciecha Brola dostępne na stronie https://wbdata.pl/category/wybory/.
Ponieważ programuję zazywczaj w języku Python zastanawiałem się jak trudne byłoby przygotowanie podobnych wizualizacji korzystając tylko z tego języka oraz z narzędzi Open Source.
Oczywicie poniższe wizualizacje proszę traktować jako formę zabawy z formą. Przygotowanie map i wizualizacja na nich danych jest dziedziną o długiej i bogatej historii. Wiele przykładów i dobrych praktyk można odnaleźć w (elektronicznym) opracowaniu GUS Mapy statystyczne. Opracowanie i prezentacja danych
Krok 1 - zebranie danych
Do przygotowania wizualizacji potrzebujemy danych źródłowych:
- wyników wyborów ze strony https://wybory2018.pkw.gov.pl/pl/dane-w-arkuszach
- danych geograficznych dotyczących podziału administracyjnego kraju http://www.gugik.gov.pl/pzgik/dane-bez-oplat/dane-z-panstwowego-rejestru-granic-i-powierzchni-jednostek-podzialow-terytorialnych-kraju-prg
- jednostki_administracyjne.zip - w formacie SHAPEFILE
W poniższym przykładzie oba pliki ZIP zostały umieszczone w katalogu ../data/raw.
Krok 2 - narzędzia
Potrzebujemy programów:
- Python 3.6+
- Jupyter
Oraz bibliotek:
pandasinumpy(manipulacje danymi)xlrd(wczytywanie danych z arkuszy Excel)matplotlibiseaborn(wizaualizacja)geopandasidescartes(obróbka i wizualizacja danych kartograficznych)
# import potrzebnych bibliotek i ustawienia katalogów
%matplotlib inline
import os
import re
import zipfile
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
import geopandas
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(style="white", font_scale=1.2)
DATA_DIR = "../data/raw"
# przydatne funkcje
def read_excel_from_zip(zip_filename, regex, **kwargs):
"""wczytywanie arkuszy Excel z archiwum ZIP"""
z = zipfile.ZipFile(zip_filename, mode="r")
names = sorted(z.namelist())
names = list(filter(lambda x: re.match(regex, x), names))
dfs = []
for fn in names:
f = z.open(fn)
try:
df = pd.read_excel(f, **kwargs)
dfs.append(df)
except pd.errors.EmptyDataError:
pass
return pd.concat(dfs, axis=0, sort=False, ignore_index=True)
def read_shape_from_zip(zip_filename, entry_name_regex):
z = zipfile.ZipFile(zip_filename, mode="r")
dbf_name = list(filter(
lambda x: re.match(entry_name_regex + r'.*\.dbf$', os.path.basename(x)),
z.namelist()
))[0]
z.close()
return geopandas.read_file(dbf_name, encoding='utf-8', vfs='zip://'+zip_filename)
def add_legend(ax, labels, colors, legend_kwds=None):
from matplotlib.lines import Line2D
patches = []
for col in colors:
patches.append(
Line2D([0], [0], linestyle="none", marker="s",
markersize=10,
markerfacecolor=col,
markeredgewidth=0)
)
if legend_kwds is None:
legend_kwds = {}
legend_kwds.setdefault('numpoints', 1)
legend_kwds.setdefault('loc', 'best')
ax.legend(patches, labels, **legend_kwds)
Krok 3 - Wczytanie danych
Zakładam, że dane dotyczące wyborów (wójtów/burmistrzów i prezydentów) zostały zapisane w pliku
samo2018-wybbp.zip, a dane dotyczące podziału administracyjnego zostały zapisane w pliku jednostki_administracyjne.zip.
Wszystkie powyższe pliki powinny zostać umieszczone w katalogu zdefiniowanym w zmiennej DATA_DIR.
wybory2018 = read_excel_from_zip(
os.path.join(DATA_DIR, 'samo2018-wybbp.zip'),
'2018-kand-wbp-I-tura.xlsx',
converters={'TERYT':str, 'TERYT\nm. zam.': str}
)
woj = read_shape_from_zip(os.path.join(DATA_DIR, "jednostki_administracyjne.zip"), "woj")
powiaty = read_shape_from_zip(os.path.join(DATA_DIR, "jednostki_administracyjne.zip"), "powiaty")
gminy = read_shape_from_zip(os.path.join(DATA_DIR, "jednostki_administracyjne.zip"), "gminy")
Krok 4 - Przygotowanie danych
Możemy zerknąć do do wczytanych tabel, najbardziej przydatne będą tabele wybory2018 i gminy.
display(wybory2018.iloc[:,:7].head(1))
display(gminy.iloc[:,:6].head(1))
| Tura | TERYT | Gmina | Powiat | Województwo | Rodzaj gminy | Urząd | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 020101 | Bolesławiec, m. | bolesławiecki | dolnośląskie | miejska | P |
| iip_przest | iip_identy | jpt_sjr_ko | jpt_kod_je | jpt_nazwa_ | jpt_nazw01 | |
|---|---|---|---|---|---|---|
| 0 | PL.PZGIK.200 | 4ed7022d-98d4-4d77-a669-d991d57b76c2 | GMI | 0222033 | Wołów | None |
Do połączenia obu tabel użyjemy kolumn wybory2018.TERYT oraz gminy.jpt_kod_je
(ograniczonej do pierwszych 6 cyfr, siódma cyfra oznacza rodzaj gminy i nie jest używana w danych PKW). Więcej informacji o systemie TERC: https://pl.m.wikipedia.org/wiki/TERC
gminy['TERYT'] = gminy['jpt_kod_je'].str[:6]
g = wybory2018.groupby('TERYT')
gm = wybory2018[wybory2018['Płeć']=='M'].groupby('TERYT')
gk = wybory2018[wybory2018['Płeć']=='K'].groupby('TERYT')
# policzmy podstawowe statystyki
gminy['liczba_kandydatow'] = gminy['TERYT'].map(g.size()).fillna(0).astype(int)
gminy['liczba_kandydatow_m'] = gminy['TERYT'].map(gm.size()).fillna(0).astype(int)
gminy['liczba_kandydatow_k'] = gminy['TERYT'].map(gk.size()).fillna(0).astype(int)
# oraz skopiujmy podstawowe informacje
gminy['rodzaj'] = gminy['TERYT'].map(g['Rodzaj gminy'].first()).fillna("?")
gminy['urzad'] = gminy['TERYT'].map(g['Urząd'].first()).fillna("?")
Sprawdźmy czy wszystkie obliczenia zostały prawidłowo wykonane.
gminy.groupby('rodzaj').size().plot(kind='bar', title='Liczba gmin wg rodzaju', rot=1, figsize=(10, 3))
plt.gca().yaxis.grid(True, alpha=0.4)
sns.despine()
plt.show()
g = gminy.groupby('liczba_kandydatow').size()
g = g.reindex(range(g.index.min(), g.index.max()+1))
g.plot(kind='bar', title='Liczba gmin wg liczby kandydatow', rot=1, figsize=(10, 3))
plt.gca().yaxis.grid(True, alpha=0.4)
sns.despine()
plt.show()
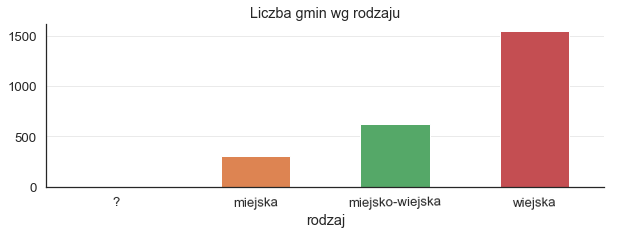
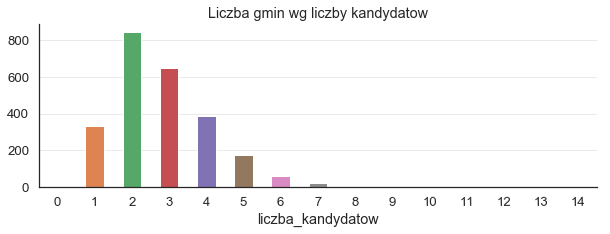
Trochę niepokojący jest fakt istnienia gmin z 0 liczbą kandydatów, później sprawdzimy czym to jest spowodowane.
Krok 5 - Wizualizacje
Zacznijmy od najbardziej podstawowych wizualizacji, np. jak wygląda rozkład liczby kandydatów w wyborach
na wójtów/burmistrzów/prezydentów w całym kraju. Przy użyciu biblioteki geopandas (http://geopandas.org/) jest
to bardzo proste i nie różni się od generowania wykresów dla biblioteki pandas.
gminy.plot(column='liczba_kandydatow', cmap='OrRd', figsize=(10, 10))
plt.show()
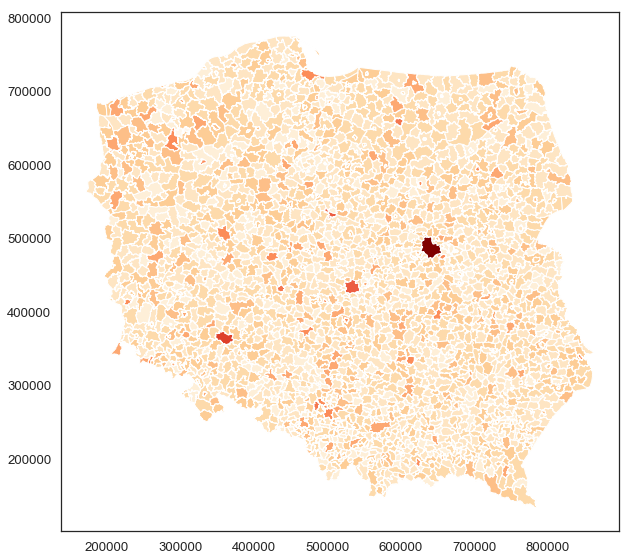
Zauważmy, że współrzędne X i Y zostały w dosyć specyficzny sposób zakodowane
(szczegóły kodowania można znaleźć w plikach *.prj archiwum jednostki_administracyjne.zip). Więcej informacji można też odnaleźć w:
Wikipedia Państwowy system odniesień przestrzennych
Możemy jednak trochę popracować nad warstwą prezentacji powyższego wykresu.
fig, ax = plt.subplots(figsize=(14, 14))
gminy.plot(column='liczba_kandydatow', cmap='OrRd', linewidth=0.5, ax=ax)
# dodajmy legende (mozna też dodać legend=True, ale wtedy jest zbyt duża)
vmin, vmax = gminy['liczba_kandydatow'].min(), gminy['liczba_kandydatow'].max()
sm = plt.cm.ScalarMappable(cmap='OrRd', norm=plt.Normalize(vmin=vmin, vmax=vmax))
sm._A = []
fig.colorbar(sm, shrink=0.5, ax=ax)
# dorysujmy granice województw
woj.plot(ax=ax, facecolor='none', linewidth=1, alpha=0.1, edgecolor=sns.xkcd_rgb['black'])
ax.set_title("Liczba kandydatów wg gmin")
ax.grid(False)
ax.set_axis_off()
plt.tight_layout()
plt.show()
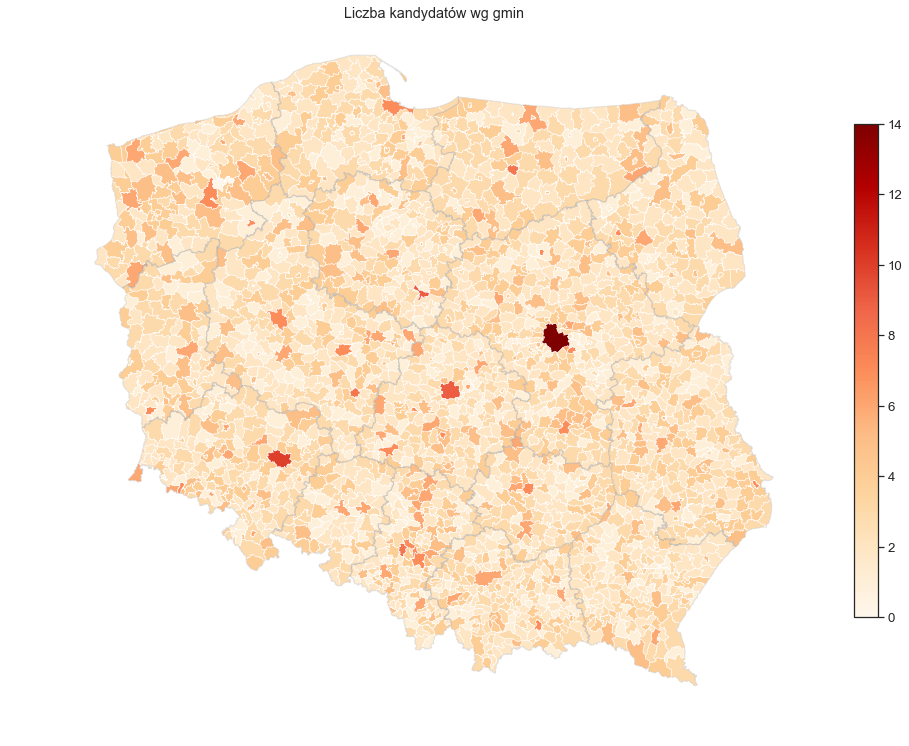
A teraz sprawdźmy gdzie jest gmina bez kandydatów?
display(gminy[gminy.liczba_kandydatow==0].iloc[:, :7])
| iip_przest | iip_identy | jpt_sjr_ko | jpt_kod_je | jpt_nazwa_ | jpt_nazw01 | jpt_organ_ | |
|---|---|---|---|---|---|---|---|
| 2458 | PL.PZGIK.200 | a6bdb37b-e73e-4902-b9b8-db403eb8e109 | GMI | 3203042 | Ostrowice | None | None |
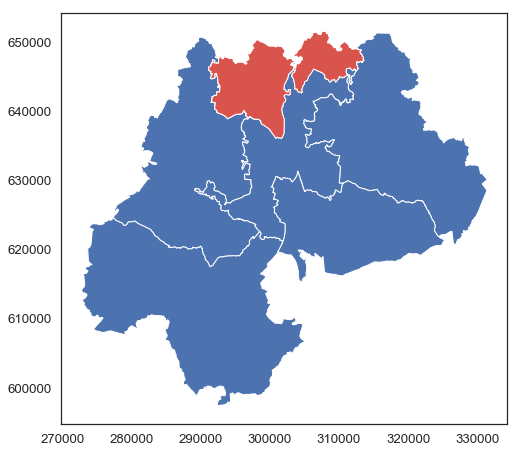
Wg wikipedii ta gmina przestała istnieć i zostanie rozdzielona (od 2019-01-01) pomiędzy sąsiednie gminy
(https://pl.wikipedia.org/wiki/Ostrowice_(gmina)), podział administracyjny
na dzień 2018-11-14 jeszcze tego nie uwzględnia, ale komisja wyborcza już tak:
https://wybory2018.pkw.gov.pl/pl/geografia/320306.
Zobaczmy jak wygląda podział w wg danych z jednostki_administracyjne.zip.
fig, ax = plt.subplots(figsize=(8, 8))
gminy[gminy.TERYT.str.startswith('32030')].plot(ax=ax)
gminy[gminy.TERYT.str.startswith('320304')].plot(ax=ax, color=sns.xkcd_rgb['pale red'])
plt.show()
No dobrze ale przejdźmy do meritum i zobaczmy jak odtworzyć przykładową wizualizację ze strony https://wbdata.pl/wybory-samorzadowe-2018-kandydaci/ dotyczącą gmin w których był tylko jeden kandydat.
fig, ax = plt.subplots(figsize=(12, 12))
gminy.plot(color=sns.xkcd_rgb['silver'], linewidth=0.1, ax=ax)
gminy[gminy.liczba_kandydatow==1].plot(color=sns.xkcd_rgb['pale red'], linewidth=0.1, ax=ax)
add_legend(ax,
['gminy z jednym kandydatem', 'pozostałe gminy'],
[sns.xkcd_rgb['pale red'], sns.xkcd_rgb['silver']],
legend_kwds={'loc': 'lower left', 'frameon': False}
)
# dorysujmy granice województw
woj.plot(ax=ax, facecolor='none', linewidth=1, alpha=0.25, edgecolor=sns.xkcd_rgb['black'])
ax.set_title("Gminy z jednym kandydatem", fontsize=18)
ax.grid(False)
ax.set_axis_off()
plt.tight_layout()
plt.show()
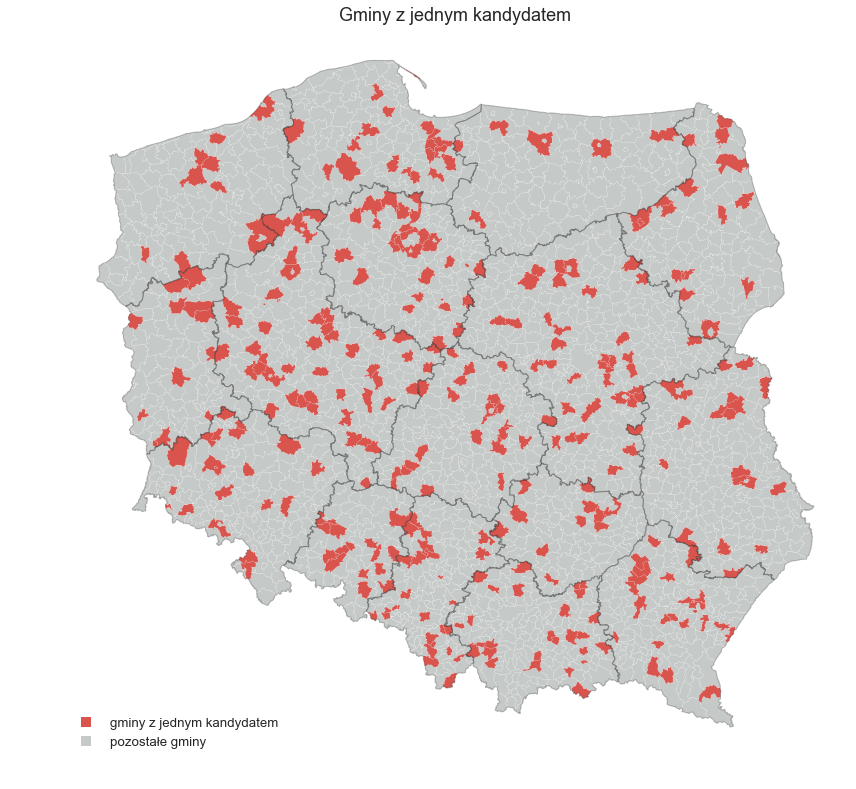
W stosunku do oryginału zmienione są kolory, ale moim zdaniem w tym wariancie gminy z jednym kandydatem są łatwiejsze do zauważenia.
Na koniec dodajmy jeszcze trochę informacji, które pokażą w jakich gminach zdarza się taka sytuacja.
sel = gminy[gminy.liczba_kandydatow==1]
g = pd.concat([
gminy.groupby('urzad').size().rename("razem"),
sel.groupby('urzad').size().rename("k1")
], axis=1, sort=False).fillna(0).reindex(['W', 'B', 'P'])
c0 = sns.xkcd_rgb['silver']
cb = sns.xkcd_rgb['pale red']
cw = sns.xkcd_rgb['orange']
plt.figure(figsize=(18, 12))
G = gridspec.GridSpec(4, 6)
ax = plt.subplot(G[0:4, 0:4])
gminy.plot(color=c0, linewidth=0.1, ax=ax)
sel[sel.urzad=='B'].plot(color=cb, linewidth=0.1, ax=ax)
sel[sel.urzad=='W'].plot(color=cw, linewidth=0.1, ax=ax)
add_legend(ax,
['gminy z 1 kand. na burmistrza', 'gminy z 1 kand. na wójta', 'pozostałe gminy'],
[cb, cw, c0],
legend_kwds={'loc': 'lower left', 'frameon': False, 'bbox_to_anchor': (0, 0)}
)
woj.plot(ax=ax, facecolor='none', linewidth=1, alpha=0.25, edgecolor=sns.xkcd_rgb['black'])
ax.grid(False)
ax.set_axis_off()
ax = plt.subplot(G[1:3, 4:6])
g['razem'].plot(kind='bar', ax=ax, color=c0, rot=0)
g['k1'].plot(kind='bar', ax=ax, color=[cw, cb], rot=0, linewidth=0)
ax.set_xticklabels(["wójta", "burmistrza", "prezydenta"])
sns.despine(ax=ax)
ax.yaxis.grid(True, alpha=0.3)
ax.set_title("wg urzędu")
plt.suptitle("Gminy z jednym kandydatem", y=0.88, fontsize=20)
plt.show()
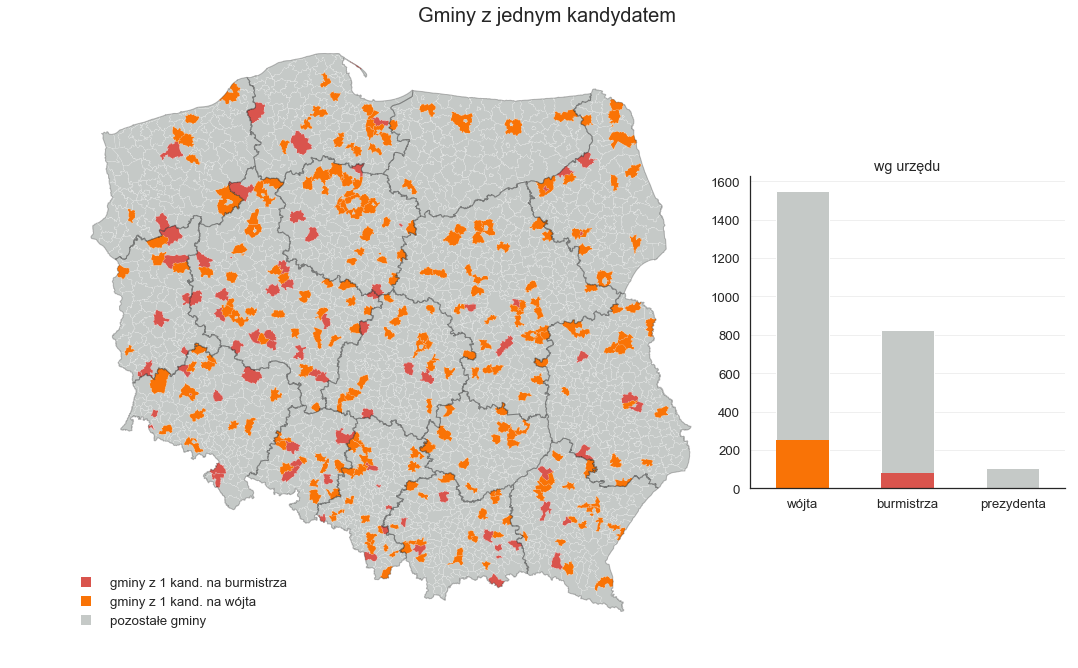
A teraz porównajmy gminy w których wszyscy kandydaci to tylko mężczyźni albo tylko kobiety.
sel_k = gminy[(gminy.liczba_kandydatow_k > 0) & (gminy.liczba_kandydatow_m == 0)]
sel_m = gminy[(gminy.liczba_kandydatow_m > 0) & (gminy.liczba_kandydatow_k == 0)]
c0 = sns.xkcd_rgb['silver']
ck = sns.xkcd_rgb['pale red']
cm = sns.xkcd_rgb['denim blue']
fig, ax = plt.subplots(figsize=(12, 12))
gminy.plot(color=c0, linewidth=0.1, ax=ax)
sel_k.plot(color=ck, linewidth=0.1, ax=ax)
sel_m.plot(color=cm, linewidth=0.1, ax=ax)
add_legend(ax,
['tylko kobiety', 'tylko męźczyźni', 'pozostałe gminy'],
[ck, cm, c0],
legend_kwds={'loc': 'lower left', 'frameon': False}
)
woj.plot(ax=ax, facecolor='none', linewidth=1, alpha=0.4, edgecolor=sns.xkcd_rgb['black'])
ax.set_title("Kandydaci wg płci", fontsize=18)
ax.grid(False)
ax.set_axis_off()
plt.tight_layout()
plt.show()
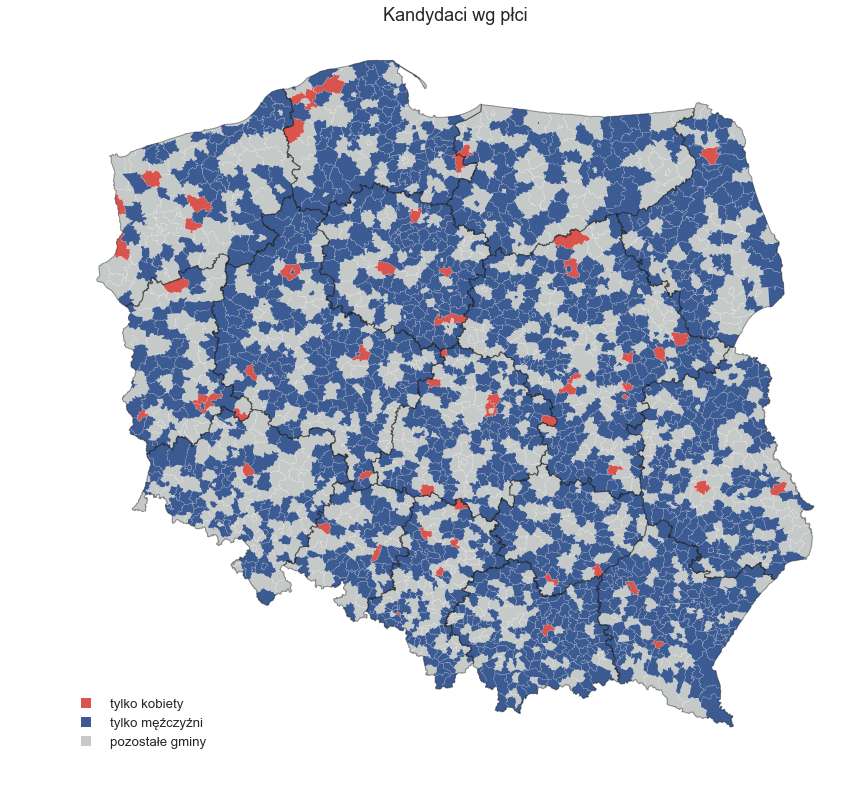
Więcej szczegółowych wizualizacji już wkrótce :)