Spis treści
- Hiberante i ORM (Object Relation Mapping)
- Architektura
- Klasy persystentne
- Jak korzystać z Hibernate?
- HQL - generowanie zapytań
- Bardziej zaawansowane przykłady
- Hibernate w aplikacjach webowych
- Narzędzia
- Źródła
Hiberante i ORM (Object Relation Mapping)
Sytuacja na rynku aplikacji biznesowych wygląda następująco:
- Większość baz danych jest relacyjna, co najwyżej z możliwością obiektowości lub przynajmniej semistrukturalności (XML).
- Aplikacje warstw pośrednich i klienckich są pisane w znacznej przewadze obiektowo.
Na styku bazy danych i oprogramowania powstaje zatem pewna niespójność. Potrzebne są odpowienie narzędzia które mogą przełożyć język relacji na język obiektów i na odwrót. Obsługa samego JDBC jest zwykle kłopotliwa przy bardziej skomplikowanych aplikacjach.
Pojawiają się następujące potrzeby:
- Trwałe i możliwie przezroczyste przechowywanie obiektów w aplikacji.
- Wyszukiwanie spośród zapisanych obiektów.
- Wykorzystanie mechanizmów bazodanowych: transakcje, odtwarzanie po awariach, autoryzacja dostępu, etc.
- Dostęp do danych obiektów przez starsze aplikacje używające paradygmatu relacyjnego.
Ponieważ w świecie biznesu mocno ugruntowały się relacyjne bazy danych, a ponadto panuje pogląd o ich przewadze efektywnościowej nad bazami obiektowymi, to narzędzia wspomagające ORM stały się bardzo popularne.
Do zadań mapowanie obiektowo relacyjnegoORM należy:
Hibernate jest obecnie jednym z najpopularniejszych rozwiązań ORM. Jest on tworzony przez firmę JBoss Inc., która właśnie została kupiona przez RedHat (10 kwietnia 2006). O jego popoularności i efektywności świadczy np. to że implementacja CMP w EJB3 na serwerze JBoss jest zaimplementowana w oparciu o Hibernate, zaś przy projektowaniu specyfikacji EJB3 skopiowano wiele rozwiązań.
Inne popularne rozwiązania ORM to:
- CMP
- JDO - specyfikacja, implementacje:
- Cayenne - ORM framework
- Hydrate - ORM, a wlasciwie RDB <--> OO <--> XML
- iBATIS - ORM (Java, .NET)
- JDX - ORM
- SimpleORM - ORM (bardzo prosty)
- TopLink (Oracle)- ORM, RDB <--> OO <--> XML
Hibernate, w odróżnieniu od JDO nie jest standartem ale konkretnym rozwiązaniem. Główne zalety w porównaniu do konkurencji to:
- Lekkość - nie trzeba używać specjalnych kontenerów, wystarczy dołączyć odpowiednią bibliotekę, można go wykorzystać zarówno do aplikacji webowych, jak i klienckich
- Brak konieczności generowania ręcznie dodatkowego kodu. W odróżnieniu np. od JDO Hibernate wymaga jedynie obecności plików konfiguracyjnych. Dodatkowe klasy wykorzystywane przez niego są generowane w czasie wykonywania.
Architektura
Hibernate opiera się na podobnych ideach i wzorcach jak inne rozwiązania ORM (JDO, CMP). Bardzo ogólnie traktując można zobrazować działanie na następującym diagramie:

Do bardziej szczegółowego diagramu trzeba podejść na dwa sposoby. Wynika to z faktu, że Hibernate jest dość elastyczny:
- Aplikacja sama zarządza transakcjami, połączeniami, etc. Używany jest tylko minimalny podzbiór funkcjonalności Hibernate.
- Aplikacja pozwala Hibernate na zarządzanie.
Ilustrują to odpowiednio diagramy:
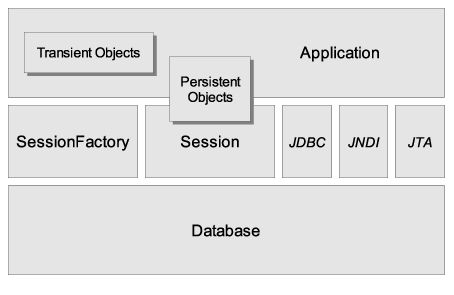
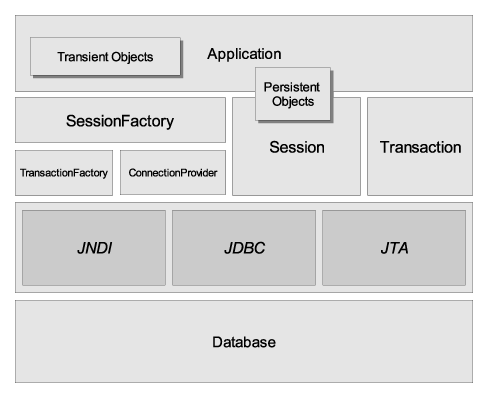
Podstawowe klasy wykorzystywane w pracy z Hibernate to:
- SessionFactory
- Session
- Transaction
SessionFactory (org.hibernate.SessionFactory)
Obiekt tej klasy dostarcza obiektów Session.
Zawiera on informacje o mapowanych obiektach - przy jego
tworzeniu wczytywana jest konfiguracja
Zwykle aplikacja ma jeden obiekt tej klasy - może on być zarządzany
np. przy pomocy Springa.
Session (org.hibernate.Session)
)
Jeden z najważniejszych obiektów Hibernate, jednocześnie
sprawiający na początku wiele problemów.
Obiekt tej klasy reprezentuje jednostkę pracy z bazą
danych, odpowiada zwykle jednemu połączeniu (Connection)
z bazą danych.
Reprezentuje jednostkę pracy z Hibernate. Odpowiada mu
np. PersistenceManager w CMP. Wszystkie obiekty persystentne są
przypisane do jakiejś określonej sesji i próba ich modyfikacji a
nawet (czasami) dostępu kończy się wyjątkiem.
Sesja jest otwierana przez SessionFactory
SessionFactory.newSession()
, a po zakończneniu jest zamykana session.close()
Jedna sesja powinna odpowiadać logicznej części programu - wykonaniu
jakiegoś zadania. Czasami (ale nie zawsze!) może to być jedna transakcja.
Przy aplikacjach www bardzo często spotykanym i łatwym w implementacji
modelem jest session-per-request. Sesja jest wtedy
otwierana na początku przetwarzania żądania i zamykana na końcu.
Najłatwiej jest to zrobić przy pomocy filtra.
Model ten sprawia jednak pewne problemy jeśli przechowujemy
w sesji html jakieś obiekty persystentne (czyli przy korzystaniu np.
z JSF, Struts...).
Transaction(org.hibernate.Transaction)
Odpowiada jednej transakcji bazodanowej. Jest związana z konretną sesją,
tworzona jest przy pomocy
Transaction tx = session.beginTransaction();
Możemy ją odwołać lub zatwierdzić
tx.commit(); tx.rollback();
Klasy persystentne
Hibernate pozwala nie tylko na uniezależnienie programisty od konkretnej
bazy danych, potrafi także zarządzać stanem obiektów persystentnych.
Programista może nie wiedzieć kiedy i jakie zapytania do bazy są
wykonywane
Obiekty klas mapowanych przez HIbernate mogą być w trzech stanach:
- Transient - obiekty są w tym stanie po utworzeniu za pomocą
new. Taki obiekt nie jest związany z żadną sesją Hibernate. Jest to
normalny obiekt Javy, może przejść do stanu Persistent
- Persistent - takie obiekty są związane z danymi w bazie
danych, a także z konkretnym obiektem klasy Session.
Hibernate wykrywa zmiany w nich i przy zakończeniu sesji wprowadza je
do bazy danych.
- Detached - obiekt znajduje się w tym stanie jeśli był
Persistent, ale odpowiednia sesja została zamknięta. Może
on być potem związany z inną sesją
Jak korzystać z Hibernate?
Do korzystania z Hibernate potrzebne są następujące składniki:
- biblioteka :)
- plik konfiguracyjny
hibernate.cfg.xml
- pliki mapujące
*.hbm.xml
Plik konfiguracyjny
W nim zawarte są dane konfiguracyjne dotyczące bazy danych na
której działamy. Tutaj
znajduje się przykład Poniżej opis najważniejszych elementów:
-
<!-- Database connection settings -->
<property name="connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="connection.url">jdbc:hsqldb:hsql://localhost/xdb</property>
<property name="connection.username">sa</property>
<property name="connection.password"></property>
W tej części podajemy standardowe informacje o połączeniu z bazą
danych, czyli sterownik, port, nazwę, użytkownika itd. Można także
podać dataSource, jeśli pracujemy na serwerze aplikacji.
-
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.HSQLDialect</property>
Hibernate potrafi współpracować z większością popularnych baz danych,
ale ponieważ składnia SQL nieco się dla nich różni, to trzeba mu podać
rodzaj bazy danych.
<mapping resource="Event.hbm.xml"/>
Bardzo ważny element - musimy zadeklarować wszystkie pliki mapujące
Pliki mapujące
Te pliki zawierają właściwy opis mapowania, czyli tłumaczenia
relacyjnego opisu danych na obiektowy i na odwrót.
Tutaj znajduje się
przykład prostego pliku mapującego. A tutaj nieco bardziej
skomplikowany przykład. Zwykle plik *.hbm.xml odpowiada
jednej klasie bądź tabeli. Dzieje się tak zwłaszcza wtedy gdy mamy
prostą strukturę, gdzie tabele odpowiadają bezpośrednio klasom.
Poniżej omawiamy podstawowe elementy pliku mapującego:
-
<class
name="cat.model.Cat"
table="CAT"
>
ten element określa klasę i tabelę której dotyczy mapowanie
-
<property
name="nick"
type="java.lang.String"
column="NICK"
length="100"
/>
ten element opisuje pojedyncze pole i odpowiadającą mu kolumnę w tabeli
-
<many-to-one
name="owner"
class="cat.model.Owner"
not-null="true"
>
<column name="ID_OWNER" />
</many-to-one>
tu mamy przykład opisu relacji wiele-do-jeden - każdy kot ma swojego
właściciela.
Możliwe są oczywiście bardziej skomplikowane mapowania. W szczególności
Hibernate wspiera różnego rodzaju dziedziczenie
Tworzenie, zapisywanie i ładowanie obiektów
Niemal każda klasa Javy może być klasą mapowaną przy pomocy Hibernate.
-
Nie może być ona finalna - wynika to z architektury, która przeciąża
klasy persystentne.
-
Powinna mieć identyfikator - Hiberante używa go do testowania równości
-
Musi mieć konstruktor bezargumentowy
-
Mapowane pola muszą być public, lub mieć odpowiednie metody get/set
Zwykle jako klasy persystentne wykorzystuje się klasy zachowujące
wzorzec JavaBean - tzn. mające odpowiednie metody get i set dla
poszczególnych pól. Przykład pokazuje klasę Cat.
-
Ładowanie obiektu z bazy. Jeżeli znamy identyfikator obiektu to
możemy go załadować z bazy. Służą do tego dwie metody:
Cat c = (Cat) session.load(Cat.class, id);
c = (Cat) session.get(Cat.class, id);
Jak widać, podajemy klasę i identyfikator i dostajemy obiekt,
który musimy zrzutować na odpowiednią klasę. Semantyka metod różni
się zachowaniem gdy nie ma elementu w bazie z tym identyfikatorem.
Wtedy get zwraca null, zaś load - wyjątek
- Modyfikacja obiektu. Jeżeli załadowaliśmy obiekt z bazy
(jest persystentny), to wszystkie modyfikacje są śledzone przez
Hibernate i na końcu sesji (przy
session.close()) zostaną zapisane.
Jeżeli chcemy wymusić wcześniejsze zapisanie zmian to sesja ma
metodę flush().
- Zapisywanie obiektu. Jeżeli utworzyliśmy nowy obiekt
to jest on w stanie transient. Aby zapisać go do bazy musmy wywołać
Cat c = new Cat();
c.setName("pus");
session.save(c);
Metoda ta zwraca nowy identyfikator jaki został nadany obiektowi
(gdy identyfikator jest generowany np. przez sekwencję).
HQL - generowanie zapytań
Jeżeli chcemy korzystać z bardziej skomplikowanych zapytań niż
select * from table
możemy konstruować zayptania korzytające z języka HQL. Jest on
bardzo podobny do zwykłego sql, ale w zapytaniach odnosimy się do klas
persystentnych, a nie do tabel. Przykład:
Wybieramy koty o imieniu Miau:
select c from Cat c where c.name='Miau' order by c.id
Wybieramy koty, których właściciel ma na imię Jan:
select c from Cat c where c.owner.name = 'Jan'
Wybieramy koty z właścicielami:
select c, o from Cat c, Owner o where c.owner.id= o.id
Tabele w zapytaniach zawsze muszą być aliasowane!
Mając obiekt Session możemy wykonać zapytanie w
następujący sposób:
Session session;
Query q = session.createQuery("select c from Cat c where name = :id");
q.setString("id", "Miau"); //ustalamy parametry (możemy je także wpisać bezpośrednio)
q.setFirst(0); //ustalamy od którego rekordu chcemy zapytania
q.setMaxList(10); //ustalamy ile maksymalnie chcemy wyników
List result = q.list()
Lista zawiera teraz obiekty typu Cat.
Możemy także używać funkcji agregujących:
select max(c.age) from Cat c
I następnie np.
q= session.createQuery("select max(c.age) from Cat");
Integer res = (Integer) q.uniqueResult()
Ostatnia metoda daje wyjątek, gdy zapytanie zwraca więcej niż jeden rekord.
Bardziej zaawansowane przykłady
Dziedziczenie
Jest to jedna z ciekawszych cech Hibernate. Omówimy tutaj
jeden z rodzajów zapisu dziedziczenia w bazie:
Małe zwierzę (SmallAnimal) ma imię i
właściciela. Może to być mysz Mouse (i ma wtedy pewną ilość
ogonów) albo ptak Bird (i
ma pewną ilość piór)
Odpowiedni element pliku SmallAnimal.hbm.xml
zawiera:
<joined-subclass name="cat.model.Bird" table="BIRD">
<key column="ID_SMALL"/>
<property name="feathers" type="java.lang.Integer" column="FEATHER"/>
</joined-subclass>
Jak widać jest to bardzo proste:). Teraz możemy np. napisać
session.createQuery(from SmallAnimal s);
i dostaniemy wszystkie zwierzęta - zarówno ptaki jak i myszy:)
Mapowanie formuł
Czasami chcemy mieć łatwy dostep do pewnych danych zagregowanych.
Np. musimy często sprawdzać ile właściciel ma kotów. Tworzenie
zapytania za każdym razem jest uciążliwe, a trzymanie tego w bazie
bezpośrednio to już zupełna herezja:). Hibernate potrafi mapować
pole klasy jako wynik pewnego zapytania np.
<property name="catsNo" type="java.lang.Integer"
formula="(select count(*) from cat c where c.id_owner = id)"/>
Tutaj znajduje się pełny
plik mapujący.
Teraz możemy się po prostu odwoływać do pola catsNo.
Nie wiem do końca jak jest z efektywnością - tzn. czy Hibernate coś
cache'uje.
Hibernate w aplikacjach webowych
Hibernate jest bardzo wygodny, szczególnie przy aplikacjach
opartych o serwlety i jsp, gdzie nie przechowujemy dużo informacji
pomiędzy poszczególnymi żądaniami. Możemy wtedy łatwo zaimplementować
odpowiednią obsługę sesji za pomocą odpowiedniego filtra.
Przykładowy kod
Narzędzia
Samodzielne generowanie plików mapujących jest oczywiście dość uciążliwe.
Dostępnych jest kilka narzędzi, które potrafią wygenerować ze schematu
bazy danych zarówno pliki mapujące jak i odpowiednie klasy.
middlegen
Jest to narzędzie służące do szeroko pojętego "przekładania" języka
relacyjnych baz danych na języki obiektowe. W szczególności ma wbudowany
plug-in, pozwalający na generowanie plików mapujących.
Można także dołączyć odpowiednie zadanie dla anta, pozwalające na generowanie
kodu źródłowego (nazywa się hbm2java).
Hibernate Synchronizer
Jest to plug-in do eclipse, pozwalający na dodawanie plików mapujących,
konfigurację i generowanie kodu klas, jak również
generowanie schematu bazy na podstawie plików mapujących. Funkcjonalność jest jak widać
bogatsza niż dla middlegena, jednak projekt jest rozwojowy i wiele rzeczy
nie działa najlepiej.
xdoclet
Xdoclet zawiera zestaw anotacji (hibernate) i odpowienie zadanie (hibernatedoclet)
pozwalające na generowanie plików mapujących na podstawie kodu klas.
Źródła: