UWAGA: treść zadania będzie sukcesywnie uzupełniana o materiały, które pomogą Państwu rozwiązać zadanie. Wszystkie modyfikacje treści będą dla porządku odnotowywane na początku strony.
Zadanie zaliczeniowe numer 2
Zespół numer 1:
Maciej Aleksander, Jagoda Jabłońska, Marcin Kostecki
Zespół numer 2:
Tomasz Krucoń, Magdalena Tarka, Klara Trzcińska
Zespół numer 3:
Darya Karaneuskaya, Agnieszka Sztyler, Mariia Savenko, Adam Zaborowski
Modyfikacje
- 16.11 Dodano sekcję "Wprowadzenie do zadania klasyfikacji pod nadzorem"
- 19.11 Specyfikacja interfejsu, drobna zmiana nazw metod, które zostały teraz przeniesione do specyfikacji interfejsu
- 20.11 Opis drzew decyzyjnych
- 23.11 Szczegóły drzew klasyfikujących
- 23.11 Lasy losowe - opis + zasada klasyfikowania na ich podstawie
- 30.11 W wyliczeniu sytuacji, gdy należy wyrzucić wyjątek ValueError był błąd - zgadzać mają się PIERWSZY (a nie drugi) wymiar X i długość y
- 30.11 Błąd OOB, warunek na ilość uczonych drzew, drzewa regresji
- 02.12 Zbiór sekwencji enhancerowych i losowych do testów
- 07.12 Drobne wyjaśnienia wątpliwości, czym jest X i y
- 15.01 Testy, kilka wyjaśnień odnośnie dokumentacji
Treść zadania
Państwa zadaniem będzie implementacja modułu do projektu biopython. Moduł będzie służył do uczenia pod nadzorem lasów losowych, które później będą mogły być użyte do klasyfikacji i regresji. Termin oddania zadania: 18.01.
Wymagania
Pierwszą czynnością powinno być założenie przez każdy zespół repozytorium projektu na githubie. Tylko członkowie zespołu powinni mieć uprawnienia do edycji, ale kod powinien być publicznie dostępny. Po założeniu repozytorium należy wysłać do mnie jego adres. Efektem końcowym projektu ma być powstanie kompletnego pakietu do biopythona, co oznacza, że znajdzie się tam dokumentacja do każdej dostępnej dla użytkownika funkcji, a kod będzie miał przemyślaną i uporządkowaną strukturę. W szczególności powinien zawierać klasy RandomForestClassifier i RandomForestRegressor. W pakiecie powinien także znaleźć się zestaw testów automatycznych.
Wprowadzenie do zadania klasyfikacji pod nadzorem
Zacznijmy od przykładu. Powiedzmy, że pracujemy w firmie handlującej samochodami i naszym zadaniem jest ocenić na podstawie naszego wcześniejszego doświadczenia, czy zaprezentowany nam przed chwilą egzemplarz należy zakupić. Oceniając samochód mamy do dyspozycji szereg jego cech. Są to np. marka, rok produkcji, stan samochodu, przebieg itd. Znamy też historię wcześniejszych decyzji naszej firmy. Nasza odpowiedź może być dwojaka: KUP lub NIE_KUPUJ. Zadanie klasyfikacji polega w tym wypadku na znalezieniu takiej funkcji, która pomoże nam podjąć decyzję o zakupie zwracając na podstawie wektora cech samochodu wartość ze zbioru {KUP, NIE_KUPUJ}. Jeśli szukając takiej funkcji weźmiemy pod uwagę wcześniejsze decyzje firmy, to proces znajdowania takiej funkcji będzie się nazywał procesem uczenia pod nadzorem. Jeśli zaś zamiast przewidywać binarną decyzję będziemy przewidywali cenę, jaką za taki samochód chcielibyśmy zapłacić, to takie zadanie nazwiemy problemem regresji.
W ogólnym przypadku dany jest zbiór tzw. przykładów uczących {v_1, v_2, ..., v_n}, dla których znane są przyporządkowania do odpowiednich klas c_1, c_2, ..., c_n. Każdy z wektorów v składa się z wartości k cech: w_1, w_2, ..., w_k. Naszym zadaniem będzie znalezienie funkcji f, która dla zadanego (być może nie widzianego wcześniej) wektora cech v = w_1, w_2, ..., w_k zwróci przewidzianą dla niego klasę c (w wypadku regresji będzie to liczba rzeczywista).
Specyfikacja interfejsu
We wszystkich poniższych opisach tablica X ma wymiary (m x n), y jest wektorem długości m.
Klasa RandomForestClassifier. Konstruktor powinien przyjmować jeden parametr - liczbę naturalną (≥ 1) n_features .
Metody:
-
fit(X, y) - uczy klasyfikator na zbiorze treningowym X (y jest wektorem, który dla każdego wiersza X zawiera klasę, do której należy ten przykład)
-
predict(X) - przewiduje najbardziej prawdopodobne klasy przykładów w X; wraca wektor długości m
-
predict_proba(X) - zwraca wektor (rozmiaru m x 1) prawdopodobieństw przynależności przykładów z X do pierwszej klasy (za pierwszą klasę rozumiemy tutaj klasę występującą w zbiorze treningowym jako pierwsza)
Klasa RandomForestRegressor. Konstruktor powinien przyjmować jeden parametr - liczbę naturalną (≥ 1) n_features .
Metody:
-
fit(X, y) - uczy klasyfikator na zbiorze treningowym X (y jest wektorem, który dla każdego wiersza X zawiera wartość zmiennej zależnej)
-
predict(X) - wynik regresji dla przykładów w X; zwraca wektor liczb rzeczywistych długości m
Kiedy wymiary lub rodzaje danych nie będą się zgadzały, należy wyrzucać wyjątek ValueError z czytelnym komunikatem. Może się to zdarzyć np. w następujących przypadkach:
- pierwszy wymiar X i długość y nie są równe
- w wektorze y przy wywołaniu fit dla klasy RandomForestClassifier znajdują się więcej niż dwie klasy
- w funkcji predict lub predict_proba drugi wymiar nie jest równy n
- w funkcji predict lub predict_proba w kolumnie numerycznej podano wartość nienumeryczną
- w funkcji predict lub predict_proba w kolumnie wyliczeniowej podano wartość, która nie występowała w tej kolumnie w zbiorze uczącym
- w funkcji fit klasy RandomForestRegressor parametr y zawiera wartości nienumeryczne
Typy danych
W tym zadaniu rozróżniamy dwa typy danych: numeryczne i wyliczeniowe. Typy numeryczne to liczby (int, float). Typy wyliczeniowe natomiast mogą stanowić mieszankę liczb, napisów i wartości logicznych. Aby dana kolumna została uznana za kolumnę o typie wyliczeniowym, wśród jej wartości musi się pojawić chociaż jedna nie-liczba.
Drzewa decyzyjne
Dla potrzeb tego zadania drzewem decyzyjnym nazwiemy drzewo, które w węzłach ma warunek logiczny używający jednej z cech, a w liściach zbiory przykładów ze zbioru uczącego spełniające wszystkie warunki w ścieżce do liścia. Przyjmijmy dla wygody, że lewy syn w drzewie będzie zawierał zawsze te przykłady, które spełniają warunek z rodzica, a prawy te, które go nie spełniają. Dodatkowo, warunki na zmiennych numerycznych będziemy zawsze zapisywali z użyciem znaku ≤, a na zmiennych wyliczeniowych - z użyciem znaku =. Poniżej znajduje się tabela z przykładowymi danymi, na których zilustrujemy działanie drzew decyzyjnych.
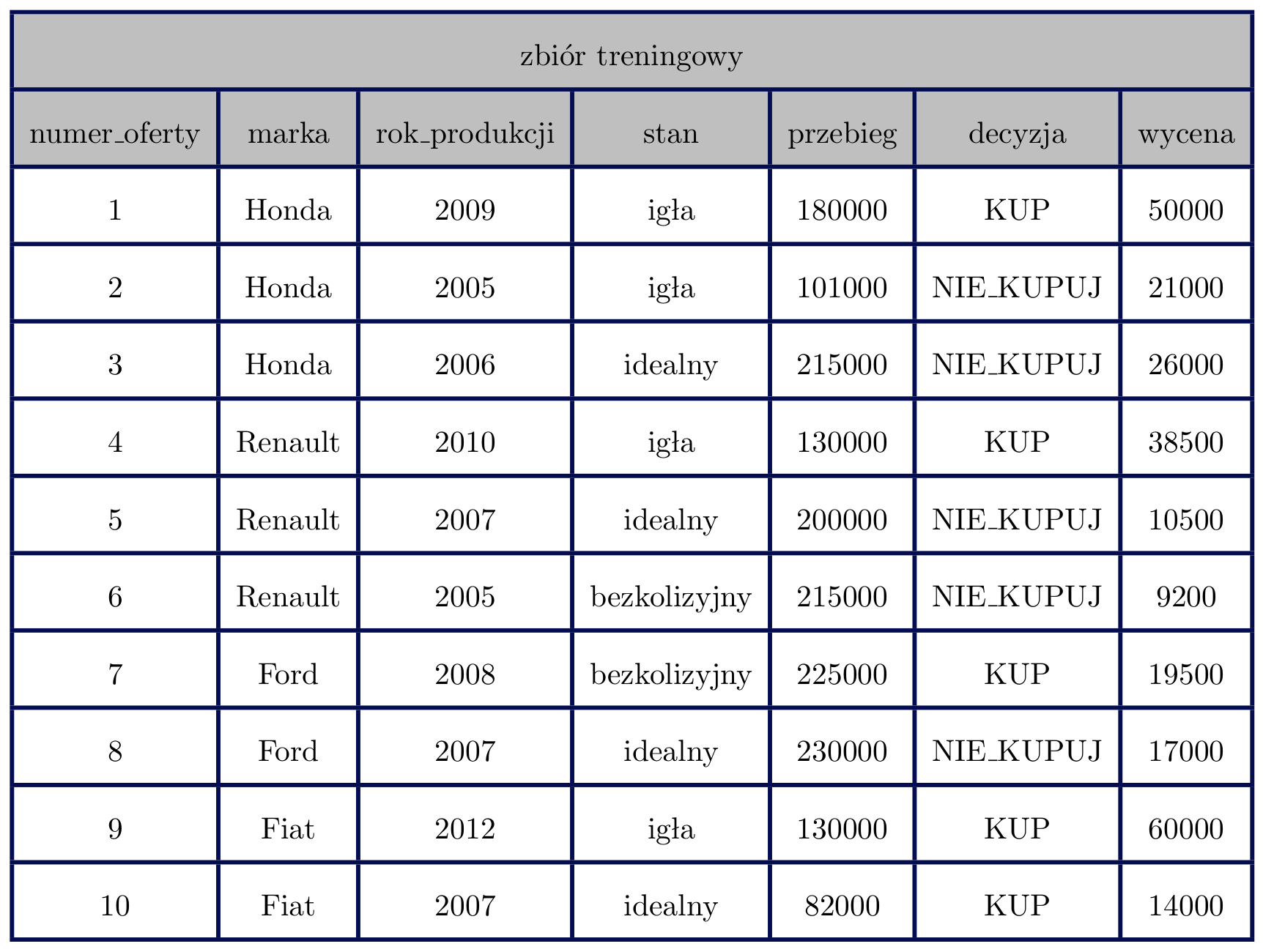 Widzimy, że kolumny numer_oferty, rok_produkcji, przebieg i wycena są typu numerycznego, a pozostałe kolumny - typu wyliczeniowego. Nasze pierwsze drzewo decyzyjne służące do klasyfikacji tych danych mogłoby wyglądać tak:
Widzimy, że kolumny numer_oferty, rok_produkcji, przebieg i wycena są typu numerycznego, a pozostałe kolumny - typu wyliczeniowego. Nasze pierwsze drzewo decyzyjne służące do klasyfikacji tych danych mogłoby wyglądać tak:
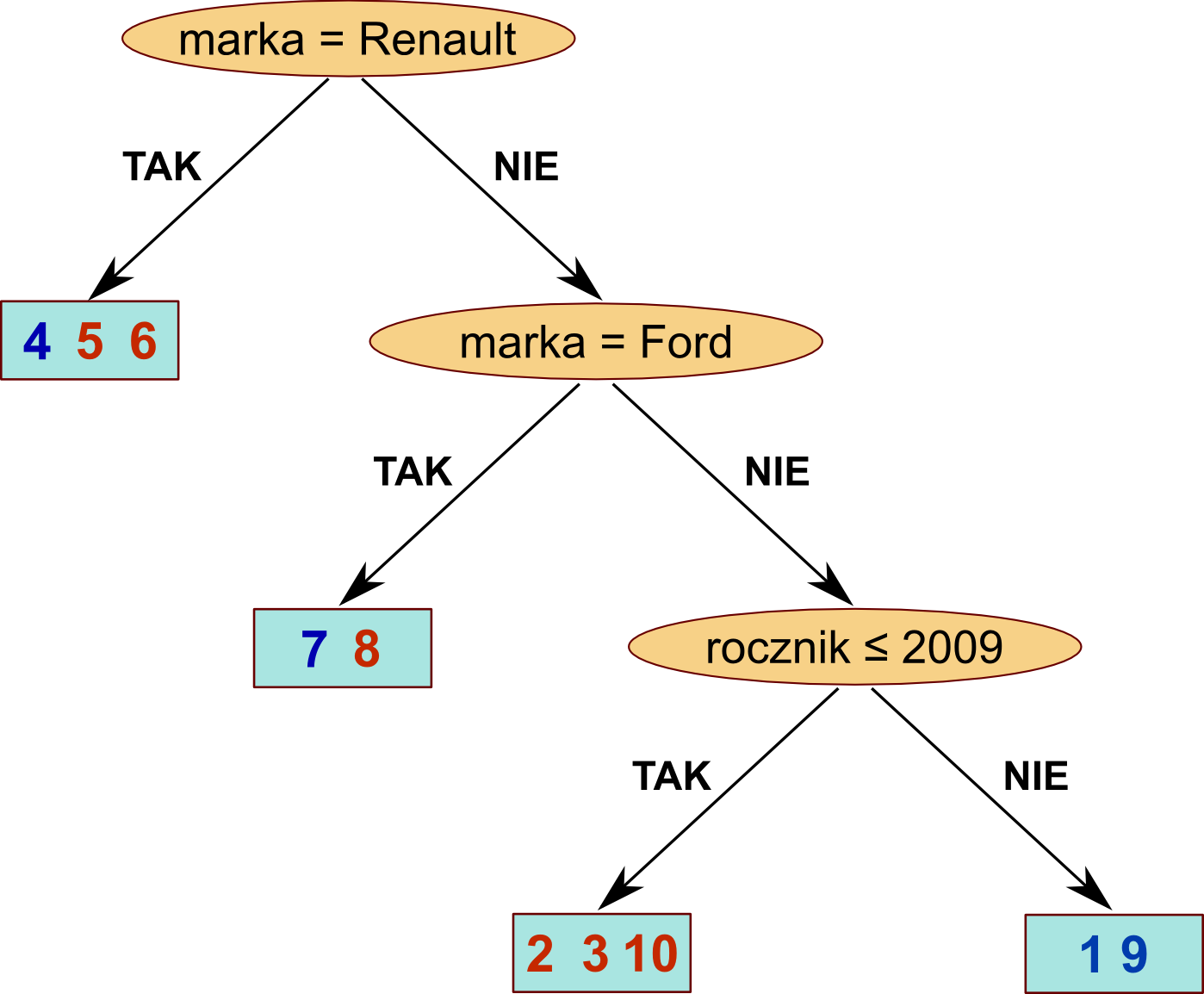 Na niebiesko oznaczone są tutaj te przykłady, dla których decyzja brzmi KUP. Pozostałe przykłady oznaczone są na czerwono. Naszym celem jest podjęcie decyzji na podstawie odpowiedzi na pytania zawarte w węzłach. Widzimy, że w tym kontekście nasze drzewo nie jest doskonałe. Np. w przypadku Fordów nie jesteśmy zupełnie w stanie przewidzieć, czy należy dany samochód kupić, czy nie. Natomiast nie-Renault i nie-Fordy ze zbioru uczącego bardzo dobrze klasyfikujemy na podstawie rocznika. Takie drzewo możemy "rozwinąć" jeszcze dalej, do momentu kiedy będziemy już potrafili jednoznacznie przyporządkować klasę przykładom ze zbioru uczącego:
Na niebiesko oznaczone są tutaj te przykłady, dla których decyzja brzmi KUP. Pozostałe przykłady oznaczone są na czerwono. Naszym celem jest podjęcie decyzji na podstawie odpowiedzi na pytania zawarte w węzłach. Widzimy, że w tym kontekście nasze drzewo nie jest doskonałe. Np. w przypadku Fordów nie jesteśmy zupełnie w stanie przewidzieć, czy należy dany samochód kupić, czy nie. Natomiast nie-Renault i nie-Fordy ze zbioru uczącego bardzo dobrze klasyfikujemy na podstawie rocznika. Takie drzewo możemy "rozwinąć" jeszcze dalej, do momentu kiedy będziemy już potrafili jednoznacznie przyporządkować klasę przykładom ze zbioru uczącego:
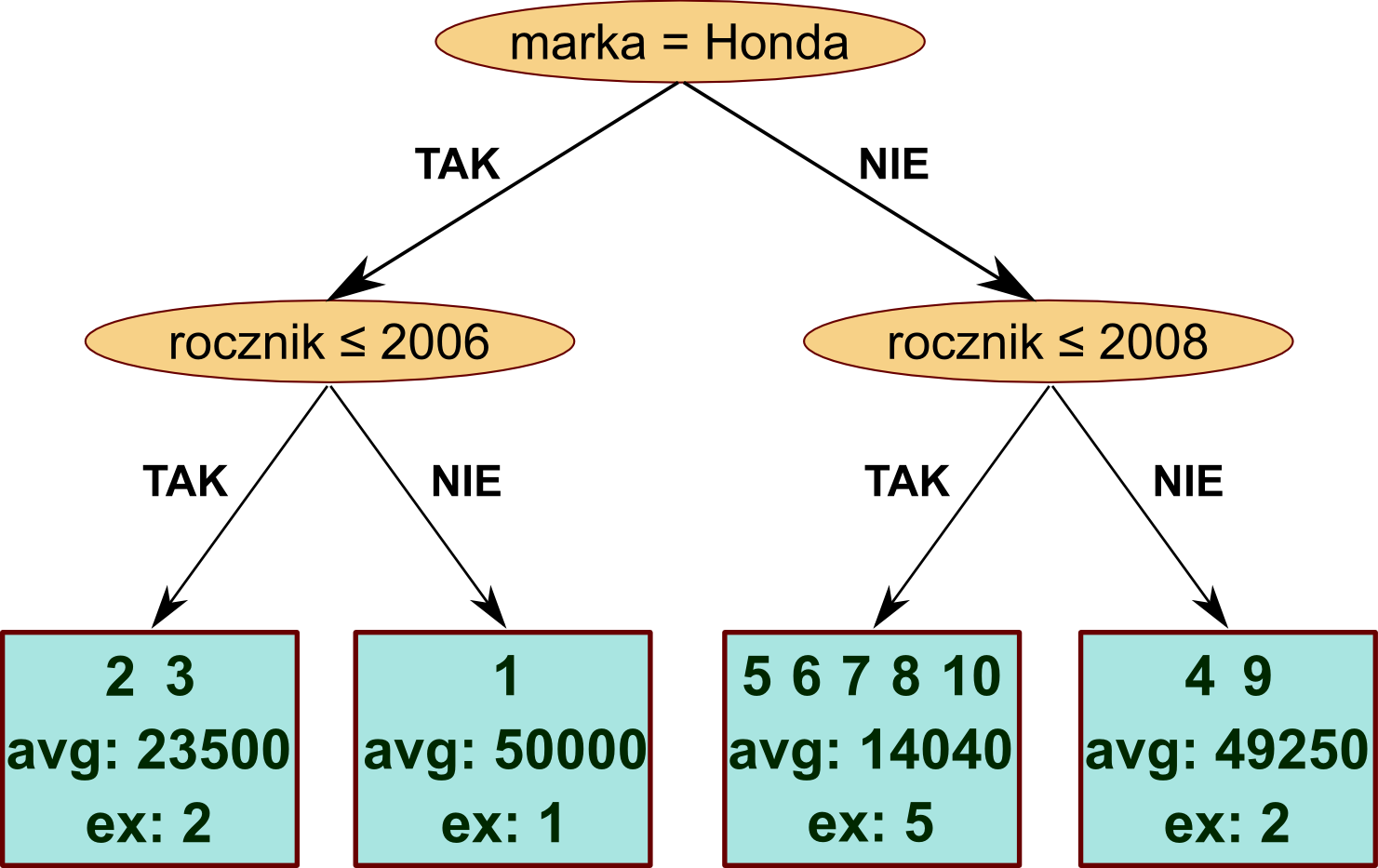
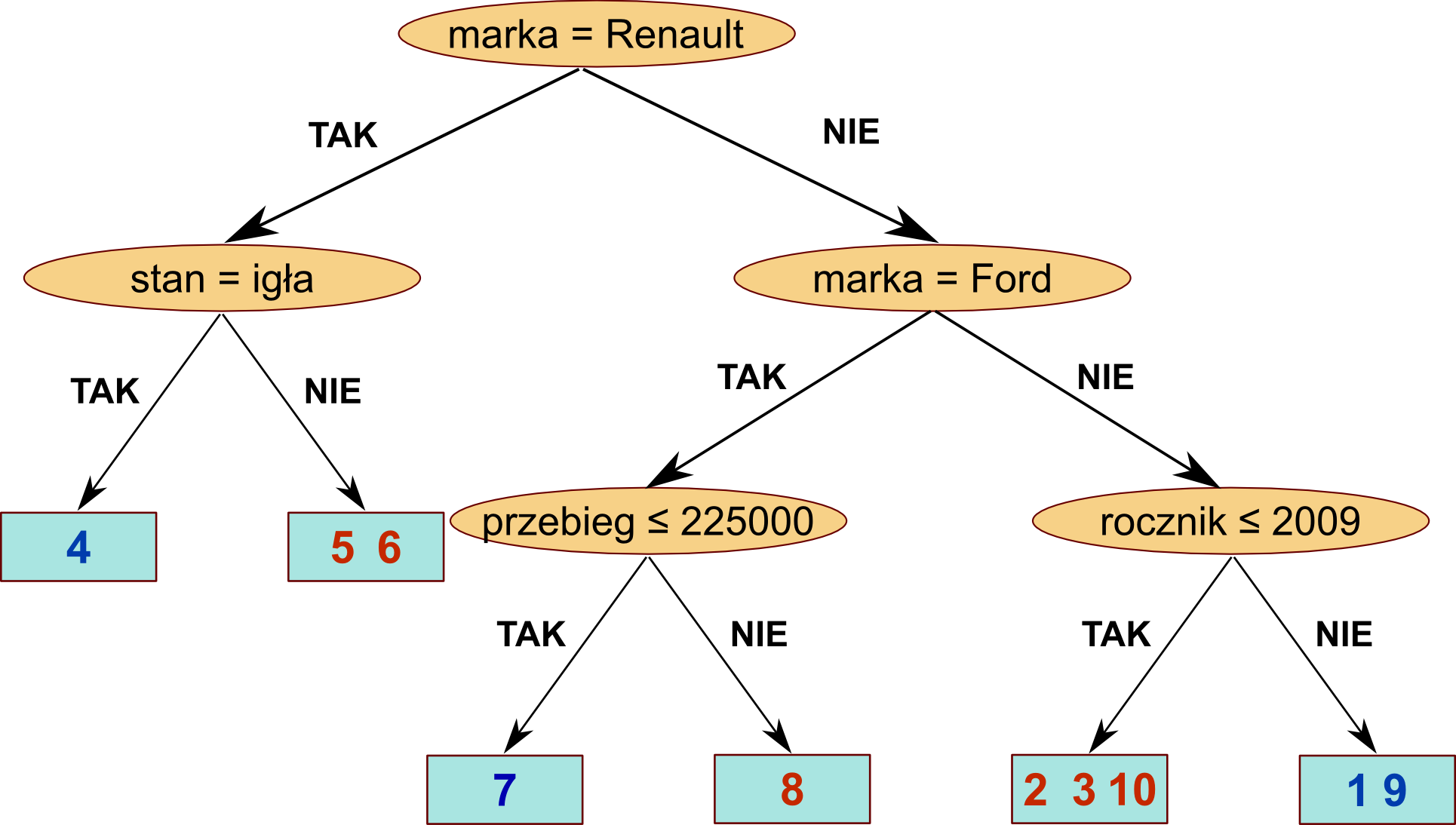 Oczywiście nie zawsze jesteśmy w stanie takie rozwinięte drzewo otrzymać - np. wtedy, gdy dwa przykłady miałyby ten sam zestaw wszystkich cech, ale inną klasę. Natomiast w przypadku regresji przykładowe drzewo mogłoby wyglądać tak (avg oznacza średnią wycenę, a ex - liczbę przykładów, które trafiły do tego liścia):
Oczywiście nie zawsze jesteśmy w stanie takie rozwinięte drzewo otrzymać - np. wtedy, gdy dwa przykłady miałyby ten sam zestaw wszystkich cech, ale inną klasę. Natomiast w przypadku regresji przykładowe drzewo mogłoby wyglądać tak (avg oznacza średnią wycenę, a ex - liczbę przykładów, które trafiły do tego liścia):
Konstrukacja drzewa klasyfikującego
Konstrukcja drzewa klasyfikującego będzie się odbywała od wierzchołka drzewa do liści w sposób rekurencyjny. Aby stworzyć drzewo klasyfikujące wybieramy najlepszy warunek dzielący przykłady ze zbioru treningowego. Następnie finalne drzewo składa się z warunku zapisanego w węźle oraz dwóch poddrzew: lewego, w którym znajduje się drzewo klasyfikujące dla przykładów spełniających warunek z węzła oraz prawego, dla przykładów go nie spełniających.
Wybór najlepszej cechy do podziału w węźle
Standardowo przeszukuje się wszystkie możliwe kombinacje: cecha + wartość, aby stworzyć podział zbioru treningowego. Ponieważ jest to bardzo kosztowna operacja, można stosować różnego rodzaju heurystyki zawężające zbiór potencjalnych kandydatów na warunek. W przypadku lasów losowych sprawa jest jeszcze prostsza. Dla każdego wierzchołka będziemy losowali n_features cech i tylko dla nich będziemy sprawdzali wszystkie możliwe wartości, aby znaleźć optymalny podział. Kryterium optymalności będzie tutaj wartość tzw. Gini impurity:
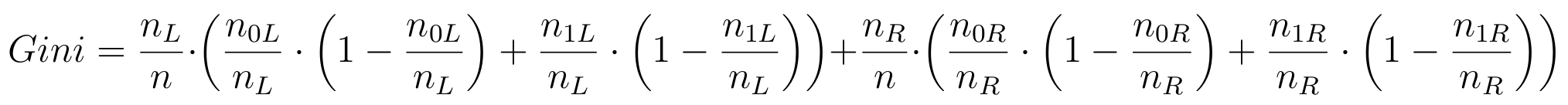 , gdzie n to liczba wszystkich przykładów, n_L i n_R to liczba przykładów, które po podziale trafią do lewego i prawego syna; n_L0 i n_L1 to liczba przykładów z pierwszej i drugiej klasy w lewym synu; analogicznie dla prawego syna. Podział powinien się odbyć za pomocą warunku, dla którego wartość Gini jest minimalizowana. Zauważmy, że dla cech numerycznych jest sens sprawdzać tylko wartości węzłowe tzn. takie, dla których istnieje przynajmniej jeden przykład w zbiorze uczącym o takiej wartości tej cechy.
, gdzie n to liczba wszystkich przykładów, n_L i n_R to liczba przykładów, które po podziale trafią do lewego i prawego syna; n_L0 i n_L1 to liczba przykładów z pierwszej i drugiej klasy w lewym synu; analogicznie dla prawego syna. Podział powinien się odbyć za pomocą warunku, dla którego wartość Gini jest minimalizowana. Zauważmy, że dla cech numerycznych jest sens sprawdzać tylko wartości węzłowe tzn. takie, dla których istnieje przynajmniej jeden przykład w zbiorze uczącym o takiej wartości tej cechy.
Głębokość drzewa klasyfikacji
Procedurę uczenia drzewa klasyfikującego możemy przerwać w dowolnym momencie godząc się na to, że w niektórych liściach będziemy mieli przykłady z obu klas. W przypadku uczenia lasów losowych procedurę uczenia pojedynczego drzewa przerywamy dopiero wtedy, gdy w danym wierzchołku możliwe są już tylko podziały prowadzące do tego, że jeden z synów będzie miał pusty zbiór przykładów ze zbioru treningowego.
Klasyfikacja na podstawie pojedynczego drzewa
Załóżmy, że w trakcie procesu uczenia drzewa decyzyjnego dostaliśmy drzewo jak w przykładach powyżej:
Aby teraz sklasyfikować nowy, nie widziany wcześniej w zbiorze treningowym przykład, np.:
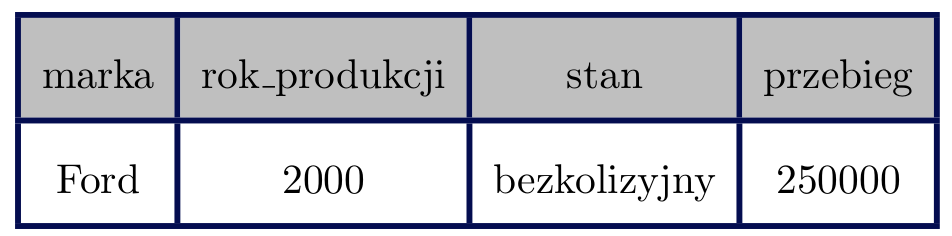 wystarczy, że prześledzimy jego ścieżkę przechodzenia po drzewie począwszy od wierzchołka. I tak sprawdzenie warunku "marka = Renault" zwróci False, co przekieruje nas do prawego syna. Warunek "marka = Ford" z kolei zwróci True, co każe nam skierować się w lewo. Ostatni warunek: "przebieg ≤ 225000" okaże się niespełniony, co skieruje nas do prawego syna i jednocześnie liścia drzewa. W tym liściu znajdują się tylko przykłady, dla których decyzja brzmiała "NIE_KUPUJ", więc taka jest też decyzja dla naszego nowego przykładu.
wystarczy, że prześledzimy jego ścieżkę przechodzenia po drzewie począwszy od wierzchołka. I tak sprawdzenie warunku "marka = Renault" zwróci False, co przekieruje nas do prawego syna. Warunek "marka = Ford" z kolei zwróci True, co każe nam skierować się w lewo. Ostatni warunek: "przebieg ≤ 225000" okaże się niespełniony, co skieruje nas do prawego syna i jednocześnie liścia drzewa. W tym liściu znajdują się tylko przykłady, dla których decyzja brzmiała "NIE_KUPUJ", więc taka jest też decyzja dla naszego nowego przykładu.
Konstrukcja drzewa regresji
Wybór najlepszej cechy do podziału w węźle
Dla drzew regresji odpowiednikiem warunku Gini impurity będzie błąd średniokwadratowy w obu synach:
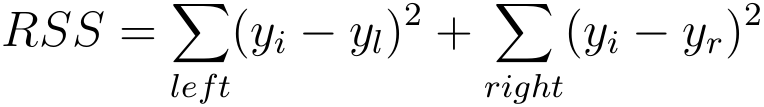 Wartości y_l i y_r to średnie wartości dla przykładów z lewego i prawego syna.
Wartości y_l i y_r to średnie wartości dla przykładów z lewego i prawego syna.
Głębokość drzewa regresji
Procedurę uczenia drzewa regresji kończymy, kiedy wszystkie podziały prowadzą do sytuacji, gdy każdy z synów zawiera 3 lub mniej przykładów.
Regresja na podstawie pojedynczego drzewa
Podobnie jak w przypadku klasyfikacji, podążanie od korzenia drzewa na podstawie warunków zawartych w węzłach doprowadzi nas do liścia. Wynikiem regresji będzie wartość (średnia), zawarta w liściu.
Lasy losowe
Las losowy (jak sama nazwa wskazuje) jest po prostu zbiorem wielu drzew decyzyjnych. Słowo "losowy" odnosi się do tego, na jakim zbiorze będą uczone kolejne drzewa decyzyjne w lesie. Załóżmy, że nasz las losowy ma być nauczony na zbiorze treningowym rozmiaru N. Procedura uczenia nowego drzewa decyzyjnego wygląda następująco:
- Losujemy ze zwracaniem (tzn. że w zbiorze treningowym mogą się pojawić kilka razy te same przykłady) dokładnie N przykładów ze zbioru treningowego. Uwaga: należy zadbać o to, aby w wylosowanych przykładach proporcja pomiędzy poszczególnymi klasami była podobna do tej w pełnym zbiorze treningowym.
- Uczymy drzewo decyzyjne na tak zdefiniowanym nowym zbiorze treningowym.
Rozmiar lasu losowego
Warunkiem zakończenia procesu uczenia nowych drzew będzie zaobserwowana stabilizacja tzw. błędu out-of-bag (OOB). Załóżmy, że nauczyliśmy już k drzew losowych. Ponieważ do nauczenia każdego z nich użyliśmy ok. 2/3 przypadków ze zbioru treningowego, dla każdego drzewa pozostaje ok. 1/3 przypadków, które nie zostały użyte do jego uczenia (out-of-bag). Weźmy teraz dla każdego przykładu c_i ze zbioru treningowego wszystkie drzewa, dla których ten przypadek był out-of-bag i niech t_i oznacza liczbę poprawnych decyzji podjętych przez drzewa, a f_i - liczbę błędnych decyzji. Błąd out-of-bag definiujemy następująco:
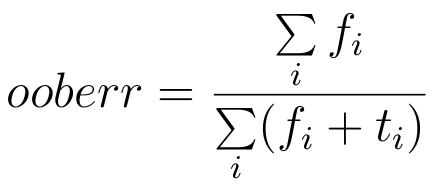 Błąd OOB należy wyliczać po każdym nauczonym drzewie. Procedura uczenia lasu losowego kończy się, kiedy stwierdzimy że dodanie ostatnich 10 drzew nie zmniejszyło błędu OOB nawet o 1%. Bardziej formalnie: niech oob_i oznacza błąd OOB klasyfikatora po nauczeniu i drzew. Procedurę uczenia kończymy, gdy:
Błąd OOB należy wyliczać po każdym nauczonym drzewie. Procedura uczenia lasu losowego kończy się, kiedy stwierdzimy że dodanie ostatnich 10 drzew nie zmniejszyło błędu OOB nawet o 1%. Bardziej formalnie: niech oob_i oznacza błąd OOB klasyfikatora po nauczeniu i drzew. Procedurę uczenia kończymy, gdy:
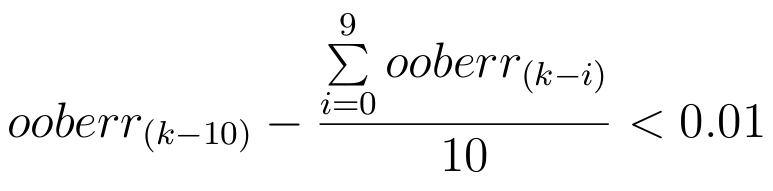 Aby ta formuła miała sens załóżmy, że minimalna liczba drzew w zwracanym klasyfikatorze będzie wynosiła 11.
Aby ta formuła miała sens załóżmy, że minimalna liczba drzew w zwracanym klasyfikatorze będzie wynosiła 11.
Klasyfikacja na podstawie lasu losowego
Klasyfikacja na podstawie lasu losowego polega na wybraniu najczęstszej decyzji zwracanej przez poszczególne drzewa. W przypadku remisów przyjmujemy, że drzewo zwraca losową klasę spośród klas, na które głosowano najczęściej.
Regresja na podstawie lasu losowego
W przypadku regresji zwracanym wynikiem jest średnia arytmetyczna wszystkich wartości zwracanych przez poszczególne drzewa.
Dane testowe
Dla potrzeb testów przygotowałem dla Państwa zestaw sekwencji z ludzkiego genomu pochodzących z tzw. enhancerów. Enhancery to fragmenty DNA, które pełnią bardzo ważną rolę w procesie regulacji transkrypcji genów. Dla nas istotną ich cechą jest to, że wiążą się do nich białka, które rozpoznają sekwencję DNA w enhancerze. W związku z tym sekwencja ta jest wysoce nielosowa. W plikach enhancers_heart.fa znajdują się sekwencje pochodzące od enhancerów aktywnych w komórkach sercowych człowieka. Natomiast w pliku random.fa znajduje się taka sama liczba sekwencji losowych z genomu człowieka. Sekwencje w obu plikach są tej samej długości i każda sekwencja znajduje się w osobnej linii. Test polegał będzie na próbie odróżnienia od siebie tych dwóch zbiorów przez Państwa klasyfikator. W tym celu jako cech użyjemy zliczeń wystąpień tzw. k-merów w sekwencji. K-mery to po prostu sekwencje długości k złożone z liter A, C, G lub T. Klasyfikator z pakietu scikit uzyskuje w eksperymencie 10 krotnej walidacji krzyżowej ok. 86% AUC przy 30 drzewach w lesie losowym. To znaczy, że dla dwóch losowo wybranych ze zbioru uczącego przykładów: jednego z pierwszej, a drugiego z drugiej klasy, potrafi poprawnie wskazać, do której klasy przynależą z prawdopodobieństwem 0.86.
Słów kilka na temat struktury pakietu, dokumentacji i testów automatycznych
Wszystkie wspomniane w poniższym akapicie pliki z moimi testami znajdą Państwo tutaj.
Chciałbym, żeby kod był utrzymany w konwencji pakietów Biopythona. W związku z tym przede wszystkim powinien to być poprawny pakiet pythonowy. Dla ułatwienia testowania proszę nazwać go RandomForests. W Biopythonie do pakietów dołączany jest jeszcze plik z testami jednostkowymi, który umieszcza się w katalogu Tests i nazywa test_RandomForests.py. Do wywoływania testów służy plik run_tests.py - wywołaniem python run_tests.py test_RandomForests.py powinno dać się uruchomić Państwa zestaw testów. W przypadku doctestów powinno dać się je uruchomić komendą python run_tests.py doctest (wymaga to umieszczenia informacji, że pakiet zawiera doctesty w pliku run_tests.py na liście DOCTEST_MODULES (więcej informacji można znaleźć tutaj. Aby uniknąć prostych błędów jeśli chodzi o strukturę klas, nazwy metod itd. przygotowałem plik z testami jednostkowymi test_RandomForests_PB.py. Po skopiowaniu Państwa modułu do katalogu Bio w pakiecie Biopython oraz skopiowaniu mojego testu do katalogu Tests, wywołanie python run_tests.py test_RandomForests_PB.py powinno zakończyć się komunikatem:
test_RandomForests_PB ... ok
----------------------------------------------------------------------
Ran 1 test in 0.003 second
Proszę też o wyczyszczenie kodu z wszelkich linijek, które w gotowym pakiecie znaleźć się nie powinny: printy, nieużywane funkcje, nieaktualne komentarze itd. Aby móc porównać się z scikitem, stworzyłem dwa testy: test_classification.py i test_regression.py. Test regresji wymaga, żeby w katalogu z testem znalazł się plik tekstowy zawierający dane wejściowe.
Jeśli ktoś zastanawia się, jak dobrze skomentować swój kod, to polecam bardzo przyjemne w obsłudze narzędzie do automatycznego generowania czytelnej dokumentacji o nazwie pdoc.
Testy użyte przy ocenianiu
Przy ocenianiu Państwa zadań użyłem prostego skryptu, który miał testować, czy najprostsze przypadki klasyfikacji są obsługiwane poprawnie. Chodziło o trzy trywialne sytuacje: kiedy w całym zbiorze uczącym jest tylko jedna klasa, kiedy zmienna objaśniana występuje również explicite jako kolumna w zbiorze uczącym i kiedy testujemy na dokładnie takim samym zbiorze, na jakim uczyliśmy. W pierwszym przypadku nie byłem specjalnie dociekliwy i rozumiem, że taka sytuacja mogłaby być też potraktowana jako przypadek błędnych danych - jeśli stosowny wyjątek i komunikat byłby zwracany, to uznałbym to za poprawne "wybrnięcie" z takich danych. Testy zamieszczam tutaj simple_test.zip. To są testy "modelowe" - we wszystkich przypadkach import wyglądał trochę inaczej, ale nie odejmowałem za to żadnych punktów - interesowało mnie tylko to, czy po udanym imporcie i dostosowaniu nazw klas wywoływany kod zachowa się poprawnie.