Wykład 1: Wprowadzenie do układów cyfrowych¶
Data: 20.10.2020
Treść
Układy cyfrowe¶
W uproszczeniu, układ cyfrowy to zbiór połączonych elementów elektronicznych,
w którym informacje reprezentowane są binarnie. Z punktu widzenia
funkcjonalności układu interesuje nas tylko, czy w danym miejscu jest stan
niski (potencjał względem masy bliski 0V, oznaczany 0 bądź L) czy
stan wysoki (potencjał względem masy bliski napięciu zasilania, oznaczany 1
bądź H). Przeciwieństwem układu cyfrowego jest układ analogowy, w którym
wykorzystywany jest szeroki zakres potencjałów.
Bramki logiczne¶
Bramki logiczne są podstawowymi elementami, z których zbudowane są układy cyfrowe – wykonują one proste operacje logiczne na wejściach. Najważniejsze typy bramek logicznych to:
NOT (jedno wejście): daje 1, gdy na wejściu jest 0.

AND (dwa lub więcej wejść): daje 1, gdy na wszystkich wejściach jest 1.

OR (dwa lub więcej wejść): daje 1, gdy na którymś wejściu jest 1.

NAND (dwa lub więcej wejść): daje 0, gdy na wszystkich wejściach jest 1.

NOR (dwa lub więcej wejść): daje 0, gdy na którymś wejściu jest 1.

XOR (dwa wejścia): daje 1, gdy na dokładnie jednym wejściu jest 1.

Bramki NAND oraz NOR są bramkami podstawowymi – jeśli umiemy zrobić bramkę NAND (lub bramkę NOR), możemy z odpowiedniej liczby takich bramek poskładać dowolny układ logiczny. Co więcej, współczesne technologie pozwalają tylko na bezpośrednią konstrukcję bramek NOT/NAND/NOR – np. bramka AND jest tak naprawdę realizowana jako bramka NAND połączona z bramką NOT.
Bramki logiczne są najważniejszym elementem składowym układów cyfrowych, ale nie jedynym – innymi często spotykanymi elementami są np. pamięć RAM, bufory trójstanowe, bufory różnicowe, itp.
Multipleksery¶
Bardzo często spotykanymi blokami w konstrukcji układów logicznych są multipleksery (zwane w skrócie MUXami). Multiplekser to blok, który ma dwa rodzaje wejść (INPUT i SELECT) oraz jedno wyjście. Wejścia SELECT wybierają jedno z wejść INPUT, którego stan będzie skopiowany na wyjście.
Najprostszy multiplekser to multiplekser 2:1, który ma następujące piny:
A: pierwsze wejście
B: drugie wejście
S0: wejście wybierające
Z: wyjście. Jeśli S0 = 0, równe wejściu A. Jeśli S0 = 1, równe wejściu B.

MUX 2:1¶
Przerzutniki, układy synchroniczne¶
Powyższe bloki są blokami kombinacyjnymi — liczą stan wyjść tylko ze stanu wejść i nie mają żadnego stanu wewnętrznego. Do trzymania stanu wewnętrznego służą bloki sekwencyjne: przerzutniki i zatrzaski. We współczesnych układach praktycznie jedynym typem używanych bloków sekwencyjnych są przerzutniki typu D:
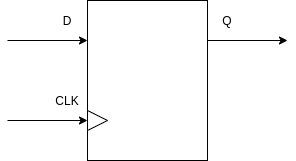
Przerzutnik typu D¶
Taki przerzutnik jest 1-bitową pamięcią:
wyjście Q pokazuje obecny stan przerzutnika
na wejściu D podajemy następny stan przerzutnika
na wejściu CLK podajemy sygnał zegarowy (zmieniający się regularnie między 0 a 1)
na każdym rosnącym zboczu zegara (w momencie, gdy CLK zmienia się z 0 na 1), przerzutnik zmienia swój stan na obecną wartość wejścia D
Układ synchroniczny to układ składający się z przerzutników i bloków kombinacyjnych — przerzutniki stanowią stan układu, a bloki kombinacyjne opisują jak obliczyć następny stan układu z obecnego. W momencie wystąpienia zbocza zegarowego, wszystkie przerzutniki jednocześnie (atomowo) zmieniają swój stan na nowy.
Realizacja układów cyfrowych¶
Od pół wieku, układy cyfrowe realizuje się w formie układów scalonych – pojedynczych kawałków krzemu, na które naniesione zostało wiele tranzystorów. Największe układy scalone mają obecnie rozmiar kilkunastu miliardów tranzystorów.
Realizując własny układ cyfrowy, mamy do wyboru następujące możliwości:
Poskładać układ cyfrowy z gotowych układów scalonych o niskiej skali integracji – seria układów 7400 bądź 4000. Jest to praktyczne tylko przy bardzo małych układach cyfrowych.
Zaprojektować i wyprodukować swój własny układ scalony (full custom ASIC – application specific integrated circuit). Jest to praktyczne tylko przy bardzo dużej skali produkcji – choć układy scalone są bardzo tanie, maski fotolitograficzne używane do produkcji są bardzo drogie (rzędu milionów dolarów). Co więcej, najmniejsza pomyłka może powodować konieczność wyrzucenia całej serii produkcyjnej (i ponownego poniesienia kosztów produkcji mask). Proces projektowania jest również bardzo skomplikowany.
Użyć programowalnego układu logicznego.
Programowalne układy logiczne¶
Programowalny układ logiczny składa się z gotowej tablicy elementów cyfrowych, których działanie oraz wzajemne połączenia mogą być zdefiniowane przez użytkownika po opuszczeniu fabryki.
Współcześnie istnieją dwa rodzaje programowalnych układów logicznych:
CPLD (complex programmable logic device):
małe (do ok. tysiąca bramek logicznych)
przeznaczone do prostej logiki łączącej bardziej skomplikowane układy
zbudowane z tzw. makrokomórek, realizujących duże sumy iloczynów (OR dużej liczby bramek AND, które też mają dużą liczbę wejść, z opcjonalnymi bramkami NOT)
zawierają wbudowaną pamięć nieulotną flash
raz zaprogramowane, są (prawie) natychmiast gotowe do pracy po włączeniu zasilania
FPGA (field programmable gate array):
duże (do milionów bramek logicznych)
przeznaczone do realizowania głównej logiki aplikacji
zbudowane z tzw. LUTów (lookup table), czyli 4-wejściowych bądź 6-wejściowych dowolnie programowalnych tabelek prawdy
oprócz LUTów zawierają również wiele gotowych komponentów przydatnych przy skomplikowanych układach, np.:
RAM
generatory zegarów
układy mnożące
gotowy rdzeń procesora ARM
układ obsługujący szynę PCI-Express
przechowują swoją konfigurację w pamięci ulotnej (SRAM) – choć są wyjątki
muszą być zaprogramowane każdorazowo po włączeniu zasilania – jeśli mają być użyte samodzielnie, wymagają osobnej kości pamięci flash na konfigurację
uruchomienie może trwać zauważalnie długo (rzędu sekundy)
W porównaniu z ASICami, zalety programowalnych układów logicznych to:
brak kosztów produkcji mask (bardzo niskie koszty jednorazowe) – opłacalne przy znacznie mniejszej skali
praktycznie natychmiastowy cykl projektowy (nie trzeba czekać kilku miesięcy, aż układy zostaną wyprodukowane przez fabrykę i przypłyną z Tajwanu)
możliwość aktualizacji projektu po dystrybucji (jak aktualizacja firmware’u)
Wady programowalnych układów logicznych:
narzut na rozmiar układu (realizacja układu na FPGA zajmuje ok. 30× więcej tranzystorów niż ASIC)
narzut na szybkość działania układu (FPGA są ok. 4× wolniejsze niż ASIC)
bardziej skomplikowana płytka drukowana i proces produkcyjny (CPLD trzeba zaprogramować przed dystrybucją, FPGA potrzebują osobnego układu programującego na płytce)
Na tym przedmiocie będziemy się zajmować wyłącznie układami FPGA (choć większość informacji będzie również przydatna przy programowaniu układów CPLD i projektowaniu ASICów).
Układy FPGA dostępne na rynku¶
Wspomnę tutaj o następujących układach FPGA:
Układy marki Xilinx (ok. 50% rynku)
Spartan: tanie, małe, bez wodotrysków. Najnowszą serią jest Spartan 7.
Artix: trochę mniej tanie.
Kintex: poważne, duże układy.
Virtex: bardzo poważne, bardzo duże, bardzo drogie układy.
Zynq: właściwie jest to procesor ARM z kawałkiem układu FPGA „na doczepkę”. Tego układu będziemy używać na późniejszych zajęciach.
Układy marki Intel (dawniej Altera) (ok. 30% rynku)
Cyclone: tanie, małe.
Arria: średniej wielkości.
Stratix: drogie, duże.
Układy marki Lattice (dawniej SiliconBlue) (mniej niż 10% rynku)
iCE40: bardzo tanie i małe. Razem z ECP5, jedyne układy FPGA sensownie wspierane przez otwarte narzędzia (projekty IceStorm i Trellis, yosys + nextpnr).
ECP5: nieco większe.
Struktura układu FPGA¶
Układ FPGA jest dwuwymiarową tablicą kafli (tile) różnego rodzaju.
Większość kafli stanowi programowalna logika – w układach Xilinxa takie kafle nazywają się CLB (configurable logic block). Dokładna konstrukcja takich kafli jest mocno zależna od konkretnego układu, ale praktycznie zawsze możemy spotkać trzy główne elementy:
Programowalną tabelę prawdy – LUT4 (4-wejściowa) bądź LUT6 (6-wejściowa). Może realizować dowolną 4- lub 6-wejściową formułę logiczną.
Łańcuch przeniesienia (carry chain) – dedykowane, nieprogramowalne połączenia między blokami logicznymi służące efektywnej realizacji dodawania/odejmowania.
Przerzutnik D (czasem programowalny tak, by stał się zatrzaskiem D) – zapamiętuje wynik z LUT.
W wielu układach, element LUT może być opcjonalnie zapisywalny w trakcie działania układu, zmieniając go efektywnie w 16- bądź 64-bitową pamięć RAM.
Oprócz programowalnej logiki, w większości układów FPGA spotkamy również następujące rodzaje kafli:
I/O block – obsługuje komunikację ze światem zewnętrznym, kontroluje jedną nóżkę układu scalonego. Można w nim ustawić najróżniejsze parametry elektryczne danej nóżki, kierunek przepływu danych, itp.
Block RAM – mały blok pamięci RAM (18 lub 36 kilobitów na jeden blok w przypadku Zynq). Może służyć jako RAM, ROM, tabela przejść w automacie stanowym, kolejka FIFO, itp.
Układ mnożący (multiplier, DSP block, itp) – dedykowany blok wykonujący operację mnożenia (mnożenie zrealizowane za pomocą zwykłej programowalnej logiki nie jest zbyt efektywne).
Układy przetwarzania sygnałów zegarowych (nazywane PLL, DCM, CCM, MMCM, …) – przesuwają fazę sygnałów zegarowych, dzielą bądź mnożą częstotliwość, itp.
Kafle FPGA są połączone ze sobą programowalnymi połączeniami – istnieje wiele linii łączących kafle ze sobą, a w każdym kaflu jest dużo programowalnych punktów połączeń (pip – programmable interconnection point), które aktywują połączenia między liniami i wejściami/wyjściami kafli.
Układy FPGA mają również dedykowaną sieć połączeń służącą do dystrybucji sygnałów zegarowych tak, aby zbocza zegara przychodziły do wszystkich elementów w miarę synchronicznie.
Po więcej szczegółów odsyłam do dokumentacji konkretnego rodzaju FPGA. W przypadku Zynq są to między innymi:
https://www.xilinx.com/support/documentation/user_guides/ug474_7Series_CLB.pdf
https://www.xilinx.com/support/documentation/user_guides/ug473_7Series_Memory_Resources.pdf
https://www.xilinx.com/support/documentation/user_guides/ug479_7Series_DSP48E1.pdf
https://www.xilinx.com/support/documentation/user_guides/ug472_7Series_Clocking.pdf
https://www.xilinx.com/support/documentation/user_guides/ug471_7Series_SelectIO.pdf
Proces projektowania układu cyfrowego¶
Projektowanie układów cyfrowych jest w wysokim stopniu zautomatyzowane. Proces ten składa się z następujących kroków:
Piszemy opis funkcjonalny układu w języku opisu sprzętu, bądź składamy nasz układ z gotowych bloków.
Istnieją trzy języki opisu sprzętu (HDL – hardware description language) akceptowane przez narzędzia większości producentów:
Verilog (najprostszy)
SystemVerilog (mocno rozszerzona wersja Veriloga, niestety mało narzędzi go wspiera)
VHDL (składniowo mocno przypomina język Ada, dość skomplikowany)
Języki te są dość stare i nieco nieporęczne. Obecnie często używa się nowszych języków, które są tłumaczone do jednego z powyższych (zazwyczaj Veriloga). Z ważniejszych można wymienić:
Chisel (na bazie Scali)
SpinalHDL (również Scala)
Clash (na bazie Haskella)
migen i nMigen (na bazie Pythona)
Na zajęciach domyślnie będziemy używać języka nMigen.
Piszemy testy do naszego układu (w tym samym języku, co sam układ, bądź w innym), opis do weryfikacji formalnej, itp.
Uruchamiamy nasze testy w symulatorze, uruchamiamy weryfikator.
Używamy automatycznych narzędzi producenta do przekształcenia naszego opisu w binarny plik konfiguracyjny (tzw. bitstream) gotowy do załadowania na układ FPGA:
Synteza: tłumaczenie (przez program, podobny ideowo do kompilatora) języka opisu sprzętu na tzw. netlistę, czyli listę instancji prymitywów obecnych w danym typie FPGA (LUTów, przerzutników, itp) i połączeń między nimi.
Place and route: rozmieszczamy zmapowane prymitywy (każdemu znajdujemy fizyczne miejsce na wybranym układzie FPGA) oraz rozplanowujemy sieć połączeń między nimi (wykorzystując zasoby danego FPGA). Może się nie udać – w tym wypadku musimy zacząć optymalizować nasz projekt, bądź kupić większy układ FPGA.
Generowanie bitstreamu: generujemy ostateczny plik konfiguracyjny dla danego układu.
Wykonujemy analizę czasową – dowiadujemy się, jakie opóźnienia mamy w finalnym układzie (po place and route) i z jaką maksymalną częstotliwością może działać. Jeśli nie jesteśmy zadowoleni z wyniku, wracamy do punktu 1.
Uruchamiamy nasze testy w symulatorze jeszcze raz, tym razem na finalnym układzie (z symulowanymi opóźnieniami).
Wysyłamy bitstream na układ FPGA i cieszymy się naszym układem.
Wrzucamy zdjęcie na twittera.
Trudności w projektowaniu układów cyfrowych¶
W fizycznym świecie istnieją tylko układy analogowe. Zadaniem projektanta sprzętu jest użyć ich tak, żeby zachowywały się jak układy cyfrowe. Jest wiele pułapek, często w nieoczywistych miejscach.
W prawdziwym świecie, sygnały elektryczne nie rozchodzą się natychmiastowo i nie zmieniają się natychmiast z 0 na 1 – istnieją stany pośrednie. Przerzutniki tak naprawdę nie łapią stanu wejścia z momentu wystąpenia zbocza, tylko z pewnej dłuższej chwili – jeśli wejście się w tym czasie zmieni, możemy bardzo boleśnie przekonać się, że świat nie jest zero-jedynkowy.
Przesyłanie danych z niskimi częstotliwościami (50MHz) jest proste – ustawiamy stan na nóżkach jednego układu, łączymy je z nóżkami innego układu, odczytujemy tam stan. Jednak w miarę zwiększania częstotliwości coraz boleśniej przypominamy sobie o istnieniu praw fizyki:
różne linie na płytce drukowanej będą miały różną długość i przez to różne opóźnienia
opóźnienia są zależne od temperatury
od pewnej częstotliwości, nasza ścieżka na płytce staje się anteną i zaczyna wymagać terminatorów na końcach
sąsiednie ścieżki na płytce wpływają na siebie przez siłę elektromagnetyczną
Nawet ze składaniem prostych funkcji logicznych bywają problemy. Czy ten układ jest poprawną implementacją MUX 2:1?
